
 В чем суть Agile с точки зрения здравого смысла и пользы для бизнеса? Давайте без применения специальных терминов просто разберёмся, что такое Agile, зачем он нужен, из чего состоит и какими инструментами добивается ключевых целей. Agile («аджайл») — слово, которое последнее время звучит из каждого утюга. Но что такое Agile и, главное, зачем этот Agile нужен? Если открыть толковый словарь, например, Оксфордский, то можно прочитать там, как минимум, два определения: 1. Able to move quickly and easily. 2. Able to think and understand quickly. То есть, чтобы быть agile, надо уметь быстро и легко двигаться и быстро соображать. Кажется, довольно полезные качества, особенно в бизнесе. Быстро соображать и быстро реагировать — это именно то, что доктор прописал, для нашего времени, иначе просто не выжить: конкуренты сожрут. В мире всё меньше отраслей, где этих конкурентов, нет. Да ещё скорость копирования практически лишает возможности вывести продукт на рынок и почивать на лаврах. Без способности быстро адаптироваться к изменениям, которую даёт так называемая «методология Agile», выживать всё сложнее.
В чем суть Agile с точки зрения здравого смысла и пользы для бизнеса? Давайте без применения специальных терминов просто разберёмся, что такое Agile, зачем он нужен, из чего состоит и какими инструментами добивается ключевых целей. Agile («аджайл») — слово, которое последнее время звучит из каждого утюга. Но что такое Agile и, главное, зачем этот Agile нужен? Если открыть толковый словарь, например, Оксфордский, то можно прочитать там, как минимум, два определения: 1. Able to move quickly and easily. 2. Able to think and understand quickly. То есть, чтобы быть agile, надо уметь быстро и легко двигаться и быстро соображать. Кажется, довольно полезные качества, особенно в бизнесе. Быстро соображать и быстро реагировать — это именно то, что доктор прописал, для нашего времени, иначе просто не выжить: конкуренты сожрут. В мире всё меньше отраслей, где этих конкурентов, нет. Да ещё скорость копирования практически лишает возможности вывести продукт на рынок и почивать на лаврах. Без способности быстро адаптироваться к изменениям, которую даёт так называемая «методология Agile», выживать всё сложнее.

В этом руководстве есть все, что вам нужно знать о показателях Agile. Поэтому, если вы хотите понять, что вообще можно измерить и как это применить, эта статья для вас. Руководство охватывает все возможные показатели Agile — их 39, которые вы, возможно, захотите использовать, и расскажет вам, что они означают, когда вы должны их использовать, как вы должны их использовать, а когда вы не должны их использовать.

Все показатели Agile
Я разбил показатели Agile на пять категорий:
- Показатели Agile Project Tools (12) – они отслеживают элементы, над которыми работает ваша команда.
- Показатели Lean Kanban (7) – они могут быть получены из инструментов Agile проекта или из других мест.
- Показатели системы управления версиями (Source Control Tools) (4) – они отслеживают коммиты, которые разработчики делают в базе кода.
- Показатели инструментов непрерывной интеграции и развертывания ПО (CI and CD Tools) (6) – они отслеживают частоту и качество сборок и автоматических тестов и развертываний.
- Показатели бизнес-аналитики (Business Intelligence Tools) (10) – они показывают, как клиенты используют ваше программное обеспечение, как развивается ваш бизнес, что клиенты думают о ваших продуктах и т.д.
Для каждого показателя Agile я объясню, что это такое, как собирать данные, когда использовать и что нужно иметь в виду.
Принципы показателей Agile
Прежде чем мы углубимся в показатели Agile, важно понять некоторые фундаментальные принципы того, что означают эти показатели и как их использовать. Я собираюсь предложить некоторые идеи, которые могут вас удивить или даже показаться противоречащими вашим ожиданиям.
Тем не менее, это важный первый шаг, и вы получите гораздо больше пользы от этих показателей Agile, если сначала у вас будет правильное понимание общего контекста и цели показателей.
Принцип № 1: Показатели Agile должны использоваться только командой
Казалось бы, это очевидно, но на самом деле, в 99% случаев люди, использующие Agile показатели, не следуют этому правилу. Чаще всего какой-то человек вне команды, обычно менеджер, хочет «измерять» или «оценивать» команду, обычно для «проверки их продуктивности». Это плохая идея по ряду причин:
- Agile показатели не измеряют продуктивность.
- Вообще не существует простого способа измерить продуктивность.
- Продуктивность не является основной мерой успеха – гораздо важнее, например, поставлять ценное программное обеспечение (бывают же непродуктивные команды, которые поставляют ценное программное обеспечение; а еще бывают очень продуктивные команды, которые не справляются с поставкой программного обеспечения или поставляют бесполезное программное обеспечение).
- Большинство Agile показателей являются отправными точками для обсуждения в команде, и если «менеджеры» лишь видят эти показатели в каком-то отчете, то они, вероятно, не участвуют в этих осуждениях.
- Большинство Agile показателей имеют смысл только в определенном контексте внутри команды, и понять этот контекст могут только члены команды.
Таким образом, команда сама должна устанавливать показатели, обсуждать и использовать их. Старайтесь избежать ситуации, когда эти показатели выходят за рамки команды и становятся известны посторонним. Вам же совсем не нужно, чтобы какой-то случайный менеджер среднего звена начал интересоваться, почему команда X имеет скорость 40, а команда Y – 50. Это не тема для продуктивного разговора.
Принцип № 2: Показатели Agile должны обсуждаться командой
Числа важны и могут помочь рассказать историю, но они должны быть частью реального обсуждения (не электронное письмо или электронная таблица, а живая беседа между живыми людьми). Простое добавление цифр в презентацию не расскажет историю. Если вы хотите рассказать историю, вплетите числа в разговор, как вы их собрали, когда, где и почему. И что вы планируете делать с этими числами, когда вы их получите (или что вы сделали с ними, если они у вас уже есть).
Принцип № 3: Показатели Agile должны использоваться как часть конкретного исследования или эксперимента
Прочитав это руководство, вы увидите, что есть множество показателей, которые можно использовать при разработке программного обеспечения (ПО). Если вы просто соберете их все, надеясь сразу понять всю картину, вы будете ошеломлены и ничего полезного не узнаете. Каждый показатель рассказывает определенную историю и может быть использован как часть конкретного исследования («с чем у нас проблемы?») или эксперимента («как мы можем это улучшить?»).
В идеале, это исследование или эксперимент получатся в результате ретроспективы или подобной диагностики. Например, команда замечает, что у них возникают проблемы с достижением целей спринта. Тогда они решают измерить время своего цикла и убедиться, что оно увеличилось. Затем они решают провести эксперимент: уменьшить количество проверок кода и снова измерить время цикла, чтобы понять, уменьшилось ли оно. Это прекрасный пример использования показателей для обсуждения, исследования и эксперимента.
1. Показатели Agile для управления проектами (Agile Project Tools)
1.1. Скорость (Velocity)
Это первое, о чем все думают, когда дело доходит до Agile показателей. И это, наверное, самый переоцененный показатель.
Как рассчитать скорость
Скорость довольно просто рассчитать. В конце спринта сложите общее количество всех стори пойнтов (Story points), которые были перемещены в «Готово» (на основе вашего определения «Готово») в этом спринте. Некоторые нюансы, которые нужно иметь в виду: важно, когда история была закончена, а не когда она началась. Все стори пойнты истории, которая началась в спринте 11, а закончилась в спринте 12, отдаются в спринт 12, а не в спринт 11. В идеале, все ваши истории должны быть в любом случае закончены в одном спринте, но важно быть последовательными с выполнением этого правила.
Стори пойнты вносятся в спринт, когда история закончена, а не когда она выпускается для клиентов, потому что заинтересованная сторона или команда могут решить приостановить работу и не предоставлять ее заказчикам в течение нескольких недель или даже месяцев (хотя это не очень хорошо и приравнивается к потерям). Тем не менее, стори пойнты стоит отслеживать, потому что скорость – это показатель того, сколько работы команда может выполнить за определенный период времени, а не того, как часто программное обеспечение выпускается для клиентов.
Что показывает скорость, а что нет
Скорость – это не показатель эффективности, результативности, компетентности или чего-либо еще. Это просто скорость, с которой определенное количество поставленных задач (формулировок проблем) превращается в проверенное программное обеспечение. Существуют сотни или тысячи причин, по которым команда может иметь определенную скорость в спринте, и 99% из них не имеют никакого отношения к навыкам или опыту команды. Скорость никогда не должна использоваться для сравнения «производительности» команд.
У показателя скорости только одна цель: предоставить команде ориентир для оценки и планирования того, сколько работы они могут выполнить за определенное время. Если менеджер вне команды спрашивает их, какова скорость команды, спросите его, зачем ему нужно это знать. Если ответ заключается в том, что он хочет сравнить эффективность команд, не говорите ему ничего (и подумайте о том, чтобы начать искать новую работу). Если ответ заключается в том, что он хочет знать, когда будет завершена определенная работа, скажите ему предположительную дату ее завершения (для этого ему не нужно знать скорость).
Другая важная вещь, которую следует помнить о скорости, заключается в том, что она не имеет ничего общего с качеством (что очень важно) или ценностью (что еще важнее, и не то же самое). Качество программного обеспечения – это степень, в которой оно соответствует ожиданиям людей, которые его разработали, – насколько оно соответствует функциональным и нефункциональным тестам, или контрольным показателям, или критериям приемлемости (требованиям заказчика). Ценность – это степень, в которой она обогащает жизнь людей, которые ее используют. Скорость не имеет отношения к этим двум понятиям: скорость просто показывает, сколько «стикеров» было перемещено с одного края доски на другой. Эти отдельные задачи могут быть не очень хорошего качества (хотя, если у вас есть приличные тесты и критерии приемлемости, оно должно быть довольно пристойным), и они даже могут быть плохими или иметь отрицательную ценность (к сожалению, большая часть программного обеспечения такова).
Это еще одна причина, по которой люди не должны использовать скорость для оценки, насколько ценна или эффективна команда. Во-первых, команда может легко скорректировать скорость, постоянно увеличивая свои оценки (и никто не может помешать им делать это, пока команда сама оценивает свою работу). Во-вторых, цифры, которые они приводят, являются оценкой сложности пользовательских историй, а не их ценности. Я предпочел бы работать в команде, выпускающей на 10 стори пойнтов качественного ПО в каждом спринте, а не в команде с 50 стори пойнтами за мусорное ПО, которое никому не нужно.
Как использовать скорость
Я обычно беру скользящее среднее значение скорости из трех последних завершенных спринтов и использую его как оценку скорости команды для будущих спринтов. Это может позволить команде предсказать, сколько они могут выполнить в течение следующих нескольких спринтов. Имейте в виду, что из-за изменений в команде, внешней среде, контексте продукта и т.д. скорость может постоянно меняться. Таким образом, вы не сможете использовать свое текущее [скользящее] среднее значение больше, чем на несколько спринтов. Показатель скорости также может быть входом в график выполнения работ (диаграмму сгорания или выгорания задач) для визуализации прогресса в достижении вехи (milestone).
В некоторых случаях скорость фактически не нужна для выполнения такого типа планирования (мы поговорим об этом ниже, см. Пропускную способность истории). Если единственная причина, по которой вы ставите стори пойнты историям, заключается в том, что вы используете скорость для планирования вперед, рассмотрите возможность отказаться от оценок и перехода к Пропускной способности.
1.2. Дисперсия скорости и стандартное отклонение (Velocity variance and standard deviation)
В идеале команды должны показывать довольно постоянную скорость, в идеале – с постепенным увеличением. Большие провалы или скачки скорости – не очень хорошие признаки. Вы можете проверить скорость, вычислив дисперсию вашей скорости. Дисперсия равна разности средней арифметической квадратов всех вариант статистической совокупности и квадрата средней самих этих вариант. Если вы хотите использовать среднеквадратичное отклонение (общий показатель, используемый в статистике), просто возьмите квадратный корень из дисперсии.
Пример:
Средняя скорость команды составляет 30 стори пойнтов. За последние четыре спринта скорость составляла 25, 35, 40 и 20. Итак,
- 30 в квадрате = 900.
- 25 в квадрате = 625.
- 35 в квадрате = 1225.
- 40 в квадрате = 1600.
- 20 в квадрате = 400.
- (625 + 1225 + 1600 + 400) / 4 = 3850 / 4 = 962,5.
- 962,5 – 900 = 62,5.
Ваша дисперсия 62,5. Вместо нее вы можете использовать среднеквадратичное отклонение, равное примерно 7,9. Это довольно высокое отклонение от среднего значения 30, поэтому команда может подумать о том, как обеспечить более стабильную скорость. Если вы хотите узнать больше о дисперсии и отклонениях, вы можете найти много отличных онлайн-ресурсов для изучения статистики.
1.3. Предсказуемость скорости (Velocity predictability)
Другой интересный показатель – это степень, в которой скорость соответствует запланированной командой. Например, если команда при планировании закладывает в спринт 30 пойнтов работы, но затем выдает 27 (или, наоборот, 32), это интересная информация, особенно если эта ситуация постоянно повторяется. В идеале команда должна работать в предсказуемом устойчивом темпе. Убедитесь, что эти цифры не используются для осуждения команды из-за ее плохой способности оценивать объем работы. Есть много факторов, которые могут повлиять на оценку (и скорость) команды, и многие из них являются внешними [вне зоны вашего контроля].
Как измерить предсказуемость
Чтобы измерить предсказуемость, просто возьмите разницу между запланированными пойнтами работ и пойнтами выполненных работ. Вы также можете использовать отношение между указанными пойнтами, что нагляднее для разных команд, в т.ч. с необычно высокой или низкой скоростью. Для этого необходимо преобразовать число в проценты, разделив его на скорость и умножив на 100.
Пример:
Команда планирует 30 пойнтов в спринте и поставляет 27. Они не добрали 3 пойнта, или 10 процентов (3/30 * 100). На следующий спринт они запланировали 32 пойнта и поставили 34. Они перебрали 2 пойнта, или 6,25 процентов (2/32 * 100). Убедитесь, что эти цифры не выходят за пределы команды: их не нужно сообщать руководству.
1.4. Рецидив (Recidivism)
Это интересный показатель: отношение пользовательских историй, которые возвращаются к разработчикам после выпуска. Обычно это происходит из-за неудачного теста QA (хотя могут быть и другие причины, например, изменились требования и т.п.). Вы можете рассчитать его, разделив общее количество завершенных пользовательских историй, которые вернулись в разработку, на общее количество завершенных историй. Если история возвращалась в разработку несколько раз, посчитайте ее один раз (хотя это не очень хороший знак). Наверняка вы хотите снизить рецидив до как можно меньшего числа, в идеале до 0%. Если оно превышает 10% или 20%, это вызывает серьезную обеспокоенность и, вероятно, указывает на проблему с качеством (это может быть качество кода, технического задания, тестирования, даже данных или среды).
1.5. Коэффициент первого прохода (First-time pass rate)
Этот показатель похож на рецидив. Это процент тестовых сценариев, которые проходят с первого раза. Просто возьмите количество тестов, которые не прошли хотя бы один раз, и разделите его на общее количество тестов. Этот показатель можно измерять для спринта или релиза, каждый из которых можно рассматривать как отдельный показатель. Этот показатель обычно отслеживают для прогресса – тестирования работоспособности новой функции, хотя вы можете измерить его и для регрессионных тестов, т.е. чтобы убедиться, что ранее разработанные функции не были сломаны. Если вы это сделаете, разделите показатели прогрессии и регрессии, поскольку они рассказывают разные истории. Уровень первого прохода в идеале должен быть близок к 100% – даже для команд без обширной автоматизации должен быть установлен некоторый разумный уровень качества. Если он ниже 90%, значит, с качеством проблема (хотя, опять же, нужно попытаться выяснить причину проблем в процессе, а не нападать на людей). Если вы реализуете разумную автоматизацию тестирования, то приблизиться к 100% должно быть довольно легко.
Если вы не используете тестовые сценарии, вы можете просто основывать их на пользовательских историях. В этом случае возьмите количество завершенных пользовательских историй, которые не прошли один или несколько тестов в состоянии QA, ST или SIT, и разделите их на общее количество завершенных историй за этот период. Опять же, вы можете сделать это отдельно для спринта или релиза. Пользовательские истории должны быть только для тестирования прогресса – не создавайте пользовательские истории для регрессионных тестов. Это анти-паттерн (пользовательские истории представляют собой дополнительную работу по созданию продукта, а не повторное тестирование этого продукта).
1.6. Количество дефектов на спринт (Defect count by sprint)
Это простой показатель, позволяющий увидеть, сколько дефектов вы создаете в каждом спринте. Вы подсчитываете все дефекты, которые были созданы на любом этапе спринта. Если какой-то дефект был создан дважды (хотя этого не должно происходить), просто посчитайте его один раз. Если он был исправлен в другом спринте (хотя этого тоже не должно происходить), не беспокойтесь об этом. Это просто количество созданных дефектов. Это число, которое, очевидно, должно снижаться, в идеале стремиться к нулю.
1.7. Количество дефектов на количество историй (Defect count by story count)
Это, вероятно, более полезный показатель, чем предыдущий. Это отношение предыдущего показателя (количество дефектов, созданных за время спринта) к общему количеству пользовательских историй в спринте. Проблема с использованием целого числа, такого как количество дефектов на спринт, заключается в том, что оно не учитывает, сколько историй было в спринте. Количество историй может сильно варьироваться в зависимости от размера и опыта команды, контекста проекта, количества текущих дефектов и технических недоработок и т.д. Два дефекта, возникающие в спринте с двумя историями, совсем не то же самое, что два дефекта, возникающих в спринте с 20 историями. Чтобы найти новый, более наглядный, показатель, просто разделите количество дефектов, созданных в спринте (предыдущий показатель), на количество историй в спринте. Так при одинаковом количестве дефектов (2), уровень дефектности историй будет, соответственно, 100% против 10%. Лучше рассчитывать этот показатель в конце спринта. Не забудьте включить закрытые дефекты и закрытые истории пользователей.
Пример:
Скажем, вы находитесь в конце спринта и видите, что у вас есть 2 открытых дефекта и 3 закрытых дефекта. 2 из 3 закрытых дефектов были обнаружены пару спринтов назад и только сейчас были исправлены. У вас есть 2 пользовательские истории в бэклоге, 6 в работе, 2 в QA и 2 в готовых. Вы начинаете с подсчета дефектов, открытых в этом спринте, их 3 (2 открытых и 1 закрытый, остальные 2 закрытых были обнаружены в предыдущих спринтах, поэтому они не считаются). Затем вы складываете свои истории, которые находятся на разных этапах разработки или готовы, их 10 (6 + 2 + 2). Таким образом, количество дефектов на историю составляет 3 / 10 или 30% процентов.
1.8. Коэффициент завершения историй (Story completion ratio)
Это количество историй, завершенных в спринте, по отношению к количеству историй, которые были включены в спринт. Таким образом, если команда включает в спринт 10 историй и завершает 7 из них, коэффициент завершения составляет 70%. Понятно, что хочется иметь этот показатель повыше. Для этого истории должны быть небольшими, чтобы их можно было завершить за одну итерацию. Не забудьте прибавить к включенным истории, перенесенные из предыдущих спринтов. Это фактически часть цели или обязательства спринта. И не забудьте также включить истории, которые были приостановлены во время спринта и возвращены обратно в бэклог. Иначе вы приукрасите этот показатель.
1.9. Коэффициент завершения стори пойнтов (Story point completion ratio)
Этот показатель похож на предыдущий, но вы рассчитываете его, используя количество стори пойнтов вместо количества историй. Хотя я не большой поклонник оценки историй в пойнтах, это довольно полезный показатель, который содержит больше информации, чем коэффициент завершенных историй, потому что количество историй ничего не говорит об их сложности. Скажем, команда включает в спринт 10 историй, две из которых оцениваются по 1 пойнту, а остальные восемь – по 13 пойнтов. Если команде не удалось завершить эти 2 истории с одним пойнтом, они не смогли завершить 20% от количества историй в спринте, но всего лишь 2% от общего количества пойнтов в спринте.
Как использовать этот показатель
Этот показатель дает представление о том, насколько хорошо команда прогнозирует свои возможности, т.е. насколько хорошо она выполняет планирование спринта. В идеале команда должна принимать разумные и стабильные обязательства по каждому спринту и выполнять большую часть или всю эту работу. Если регулярно случаются большие отклонения, это может указывать на несколько возможных проблем. Команда может недооценивать объем историй. На них может оказываться давление, чтобы они взяли на себя больше работы, чем они могут выполнить. И это самая серьезная проблема! Команда всегда должна чувствовать, что может свободно выбирать свои цели и обязательства в спринте. Или они делают разумный прогноз, но сталкиваются с препятствиями во время спринта, которые не позволяют им выполнять работу.
Как не нужно использовать этот показатель
Как всегда, убедитесь, что вы боретесь с проблемой, а не с человеком. Используйте методы, такие как Пять почему (Five Whys), чтобы выполнить анализ, найти корневую проблему и предложить корректирующие действия или улучшения. И убедитесь, что этот показатель не передается руководству, если только команда не согласна, что для этого есть веские основания.
1.10. Время блокировки на каждый рабочий элемент (Time blocked per work item)
Следующие два показателя описывают продолжительность влияния препятствий на ваши элементы работы. Чтобы рассчитать время блокировки для каждого рабочего элемента, сначала вам необходимо отслеживать эти блокировки (иногда называемые препятствиями) в инструменте отслеживания проекта. Большинство современных Agile инструментов для отслеживания позволяют вам помечать истории или задачи как «заблокированные», и затем предоставляют отчет о количестве времени, в течение которого объект был заблокирован. Если вы отслеживаете блокировки, то в конце спринта просто сложите все время, которое любая история или задача в этом спринте провела в заблокированном состоянии.
Сделайте это для любого объекта в спринте (т.е. всего, что простаивало какое-то время в любом состоянии рабочего процесса в спринте, включая бэклог спринта, но не бэклог продукта). Затем разделите это количество времени на общее количество объектов. Итак, если у вас было 20 историй в спринте, и в общей сложности некоторые из них (в некоторой комбинации) провели заблокированными двенадцать часов, значит, ваши истории проводят заблокированными в среднем по 36 минут каждая (12 часов – или 720 минут – разделим на 20 историй).
Как использовать этот показатель
Этот показатель говорит о том, насколько сильно препятствия мешают вашим элементам рабочего процесса. Хочется, чтобы это число было минимальным и снижалось. Если оно больше 1 часа, это вызывает беспокойство.
Как не нужно использовать этот показатель
Не используйте этот показатель, чтобы критиковать команду или находить козлов отпущения. Это показатель, который команда должна использовать для оценки, насколько сильно препятствия снижают их способность выполнять работу. Имейте в виду, что многие из этих препятствий будут вне контроля команды, поэтому не позволяйте менеджеру использовать этот показатель для обвинения команды или отдельных ее членов. Эти «блокировки» обычно являются результатом неэффективных артефактов в потоке создания ценности, таких как согласования, одобрения, передачи работ наружу и обратно и т.д.
1.11. Процент заблокированных элементов (Percent of items blocked)
Этот показатель похож на предыдущий, но вместо этого он показывает, какая доля пользовательских историй в спринте блокируется препятствиями. Он не говорит вам, как долго они были заблокированы, но сообщает, сколько (как часть от общего числа) историй заблокировано, что может быть полезно. Если вы используете в качестве показателя время блокировки для каждого элемента работы, ваши цифры могут быть искажены аномалией – всего одна история, заблокированная в течение длительного времени, может исказить среднее значение (которое в противном случае было бы низким). Вы можете исключить из расчета эту аномалию или использовать показатель процента заблокированных элементов. Вычислить его просто – вы подсчитываете количество историй, которые были заблокированы в течение спринта (включая те, что находятся в бэклоге спринта, но не обращая внимания на бэклог продукта). Затем разделите его на общее количество историй, которые находились в работе во время этого спринта. Это даст вам процент заблокированных элементов.
Как использовать этот показатель
Вы можете использовать этот показатель, чтобы определить общую частоту препятствий в команде. Желательно, чтобы это число было низким, в идеале 10% или ниже (возможно, близким к нулю). Как и предыдущий, убедитесь, что он используется для изучения возможных коренных причин и идей для постоянного улучшения, а не для того, чтобы наказывать людей — препятствия часто возникают из-за сил, неподконтрольных команде (в противном случае они бы сразу избавились бы от них).
1.12. Накопительная (кумулятивная) схема потока (Cumulative Flow Diagram)
Что это за показатель? Кумулятивные схемы или диаграммы потока (CFD) на самом деле представляют собой не показатель, а визуализацию набора базовых показателей. В частности, CFD – это линейный график, показывающий суммарные баллы работы в различных состояниях. Это сложно описать словами, но гораздо проще объяснить наглядным примером. Ниже приведена типичная кумулятивная диаграмма потока для команды. Горизонтальная ось – это время, а вертикальная ось – это истории в определенном состоянии по стори пойтнтам. Различные цвета представляют разные состояния, в которых находятся эти истории.
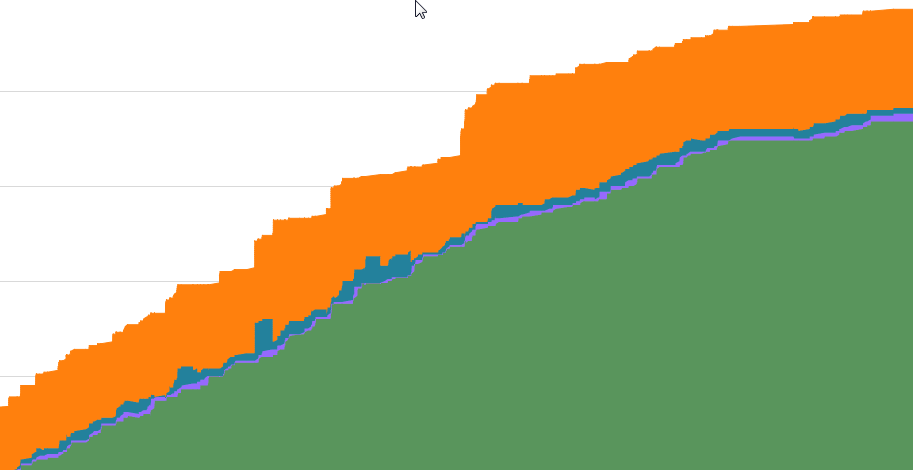
На этой диаграмме зеленым цветом представлены завершенные истории, фиолетовым – истории в обзоре спринта, синим – истории в работе, а оранжевым – истории в бэклоге.
В любой момент времени вы можете провести вертикальную линию и увидеть соотношение работы в разных состояниях. Тот факт, что вы можете видеть все состояния и изменения во времени, делает этот инструмент очень мощным и изощренным. Гораздо лучшим, чем более известные и популярные графики, такие как диаграммы сгорания и выгорания задач (которые дают нам довольно плохое представление о работе в системе).
На рисунке представлена довольно хорошая кумулятивная диаграмма потока, потому что бэклог никогда не бывает слишком большим (вы же хотите, чтобы бэклог незаметно перетекал в работу), истории постоянно завершаются, и, что самое важное, небольшой объем работы есть и в обзоре, и в работе (т.е. незавершенное производство WIP находится под контролем).
2. Показатели Lean и Kanban
В этом разделе будут описаны некоторые показатели, которые относятся к системам Lean и Kanban.
2.1. Время выполнения истории (Story Lead Time)
Время выполнения – это концепция, часто используемая в Lean и Kanban. Это общее время, прошедшее с момента, когда пользовательская история входит в систему (например, она была записана в бэклог или создана в инструменте для отслеживания проекта Agile), до того момента, пока она не будет завершена, то есть соответствует определению «Готово». Это время включает в себя время, проведенное в бэклоге. Таким образом, время выполнения истории сообщает вам, сколько времени потребуется, чтобы запрос от клиента прошел весь путь через систему. Вы можете изменить критерии для помещения истории в «Готово». Обычно это означает готовность продукта к передаче клиентам, но вы можете решить, что это должно означать фактическую передачу. При расчете скорости вы используете обычное определение готовности (что на самом деле чаще означает готовность к производству, а не передачу клиентам), потому что вы пытаетесь выяснить, как быстро ваша команда может выполнить работу и взяться за следующую историю. Время выполнения распространяется до момента, когда начинает доставлять ценность, поэтому оно полезно для определения общей скорости вашей цепочки создания ценности. Вы должны стараться сократить время выполнения заказа (во многих отношениях это гораздо более важный показатель, чем скорость).
Убедитесь, что вы учитываете все время, даже если оно включает длительные периоды ожидания. Если история входит в бэклог и находится там в течение шести месяцев, а затем берется в работу и завершается в течение одного месяца, время выполнения заказа составляет семь месяцев! Если вы подумали, что «тогда нам придется быстро перемещать истории из бэклога в работу», вы начинаете понимать важность времени выполнения заказа.
2.2. Время цикла истории (Story Cycle Time)
Время цикла истории аналогично времени выполнения заказа, но с существенным отличием. Это время, которое требуется для того, чтобы история перешла из состояния «В работе» (у вас, вероятно, есть такой или подобный статус на вашей доске Канбан или в цифровом инструменте для отслеживания проекта) до состояния «Готово». Следовательно, оно является подмножеством времени выполнения и, следовательно, [почти] всегда меньше, чем время выполнения. Время выполнения минус время цикла – это время ожидания: время, в течение которого история или заказ проводят в очереди, ожидая принятия в работу. Так же, как со временем выполнения, вы должны пытаться сократить время цикла. В идеале, ваше среднее время цикла должно составлять около половины спринта или меньше. Если ваше среднее время цикла больше, чем один спринт, у вас большая проблема, потому что вы не заканчиваете истории в одном спринте.
Как было и со временем выполнения заказа, убедитесь, что вы учитываете все время, прошедшее с момента начала работы над пользовательской историей, даже если она была заблокирована или вы по какой-то причине долго ей на занимались. Если история перемещалась вперед и назад между состояниями (например, между «В работе» и «Тестирование»), обязательно включите все это время. Часы никогда не перезапускаются; они начинают тикать, когда история только начинает обрабатываться, и останавливаются, только когда она закончена. Без исключений.
2.3. Время выполнения функции (Feature Lead Time)
Время выполнения функции похоже на время выполнения истории, но для отдельных функций вместо историй. Поскольку пользовательские истории часто объединяются и выпускаются как функция, на самом деле это полезный показатель. Он показывает, сколько времени потребуется на создание ценности, от идеи до передачи готового продукта клиенту. Как и в случае с пользовательскими историями, часы начинают тикать, как только функция входит в бэклог. Если вы хотите измерить, сколько времени нужно, чтобы доставить ценность, то часы перестают тикать, когда функция попала в руки клиентов. Если вы хотите измерить, сколько времени нужно, чтобы функция была готова к передаче клиентам, соответственно, тогда и останавливайте часы (например, фактически осталось нажать кнопку).
2.4. Время цикла функции (Feature Cycle Time)
Как и в предыдущем показателе, время цикла объекта похоже на время цикла истории, но для функций вместо историй. В нем описывается, сколько времени в среднем занимает создание функции. Как и все эти четыре показателя, вы хотите, чтобы этот показатель имел тенденцию к снижению. Разбиение историй и сюжетов на более мелкие части будет способствовать этому (и это хорошая практика для понимания). Обязательно укажите общее прошедшее время, включая ожидание и передачу обслуживания. Измерение похоже на время выполнения функции, но часы запускаются, когда функция переходит в разработку. Вы должны определить это, когда первая пользовательская история или задача, которая является частью функции, входит в разработку.
2.5. Пропускная способность историй (Story Throughput)
Это отличный и недооцененный показатель. Я считаю, что он более полезен, чем скорость, по целому ряду причин. Его чрезвычайно легко измерить и сложно обмануть. Он дает важную информацию, поощряет небольшие истории и способствует отказу от оценок. Он также очень простой: это количество историй, выполненных в каждом спринте. Все, как для скорости, только считайте истории, которые находятся в «Готовом» (независимо от того, что это значит для вашей команды), и считайте их в том спринте, в котором они были завершены, а не в спринте, в котором они были начаты.
Как использовать пропускную способность
Пропускная способность историй не говорит вам о размере историй, которые вы завершаете, но говорит о том, сколько из них вы завершаете. Здесь есть очень важный момент: если все ваши истории примерно одинакового размера, вы можете совсем отказаться от скорости и использовать пропускную способность истории.
Вот еще один важный момент: если ваши истории следуют нормальному распределению (т.е. большинство из них примерно одинакового среднего размера, с примерно равным количеством историй выше и ниже этого среднего), то вы также можете использовать пропускную способность историй для планирования графиков сгорания / выгорания. Т.е. в этом случае вы можете также использовать пропускную способность, даже если ваши истории не все одинакового размера.
Вы можете использовать среднее значение за более длинный или более короткий период (например, скользящее среднее за три спринта), чтобы использовать его в качестве основы для измерения пропускной способности вашей истории.
2.6. Время такта (Takt time)
Время такта – это необычный показатель, который больше подходит для бережливого производства (Lean Manufacturing), чем для разработки программного обеспечения по Lean. Но некоторые люди используют его, и это важная часть Lean, поэтому стоит хотя бы понять, что это такое. Время такта – это среднее время между заказами клиентов. Таким образом, если вы получаете 48 заказов от клиентов в день, ваше время такта составляет 30 минут (24 / 48 = 0,5 часа). Время такта – это показатель потребительского спроса, поэтому оно является основным показателем, используемым для управления производительностью системы в бережливом производстве (которая основано на принципах «вытягивания», а не «выталкивания»). Заказы клиентов на самом деле не влияют на «результат» в контексте программного обеспечения, поскольку программное обеспечение может быть скопировано с практически нулевыми затратами (или доставлено через Интернет в качестве услуги, практически бесплатно), поэтому время такта не так полезно в контексте создания программного обеспечения.
2.7. Коэффициент Создано / Завершено (Created to Finished ratio)
Это интересно: соотношение количества созданных историй и законченных. В каждом спринте разделите количество созданных вами историй (независимо от того, где вы их разместили или в каком состоянии они находятся) на количество завершенных историй (т.е. соответствующих вашему определению «Готово»). На ранних стадиях создания продукта это число может быть намного больше единицы. Это потому, что люди приходят с новыми идеями и пишут истории, а разработчики могут не успевать продвигать истории, пока они строят фундамент, согласовывают проекты и т.д. (Хотя, конечно, они должны стараться выдавать какой-либо работающий софт каждый спринт). Со временем это соотношение должно начать снижаться. Если вы действительно работаете с вашим бэклогом, это число, очевидно, должно быть меньше единицы. Есть даже полезный девиз: «Перестаньте стартовать, начните финишировать».
Как использовать этот показатель
Используйте этот показатель, если вы обеспокоены тем, что слишком много элементов попадает в бэклог и мало завершается. Помните, что бэклог – это форма запасов, а запасы – это форма потерь. Желательно иметь достаточно задач, чтобы обеспечить работой команду, и примерный план действий, но не более того.
3. Показатели системы управления версиями (Source Control Tools)
Системы управления (или контроля над) версиями являются фундаментальной частью разработки программного обеспечения. Их используют все, даже люди, в одиночку работающие над ПО, потому что они предоставляют историю создания новых версий и позволяют сделать откат обратно на старые. Существует два основных типа систем управления версиями: централизованные системы управления версиями (CVS, такие как SVN) и распределенные системы управления версиями (DVCS, такие как Github). Почти все переходят на DVCS, поскольку они предлагают некоторые важные преимущества. Для целей данного руководства я буду предполагать, что вы используете или можете получить доступ к данным в DVCS. Если вы используете CVS, у вас будет гораздо меньше полезных данных, и у них есть некоторые другие присущие им проблемы, поэтому я надеюсь, что вы все же перейдете на DVCS, как только сможете.
3.1. Количество и доля объединенных запросов на включение изменений (Number and proportion of merged pull requests)
Одним из простых показателей является количество объединенных запросов на включение изменений, хотя полезнее рассматривать пропорцию. Более конкретно, отношение объединенных запросов к общему количеству запросов. Если это число достаточно велико, это, вероятно, хорошо, хотя вы по-прежнему должны проводить осмысленные обзоры кода и обсуждения. Если это число немного меньше, это нормально. Запросы не всегда должны быть объединены. Иногда разработчики предлагают другой или лучший способ сделать что-то, в идеале тот, который вообще не требует изменений кода (исходный код – это обязательство, а не актив). Если число очень маленькое, это может быть предупреждением о наличии проблемы между двумя или более разработчиками. Как всегда, убедитесь, что этот показатель используется в ваших обсуждениях, а не отправляется в отчете для менеджера, который не знает контекста и ситуации с людьми, чтобы оценивать их по этому показателю.
3.2. Длительность открытых запросов на внесение изменений (Duration of open pull requests)
Это среднее время, в течение которого запрос на внесение изменений остается в открытом состоянии. Это один из тех интересных показателей Златовласки, который должен быть не слишком высоким и не слишком низким, а где-то посередине – нормальным. Если запросы на внесение изменений открыты в течение длительного времени, это может указывать на то, что по чьему-то коммиту идет много длинных споров. Да, обсуждения – это хорошо, но вы же не хотите, чтобы они продолжались вечно: решения все равно должны быть приняты. Если каждый запрос остается открытым неделю, команде будет очень сложно выполнить достаточный объем работы. С другой стороны, не нужно, чтобы он был слишком низким. Если каждый запрос закрывается через пять минут после открытия, это говорит о том, что никто на самом деле его не смотрит и не проверяет. Так может быть, потому что команда не сотрудничает эффективно, или потому что кто-то просто поторапливает команду двигаться побыстрее. Оба варианта – плохой признак, и команда должна выяснить корневую причину.
Как использовать этот показатель
Его нужно просто проверять время от времени. Ваша DVCS должна рассчитывать и показывать его автоматически; если нет, лучше найти другую систему.
3.3. Количество комментариев на запрос (Comments per pull requests)
Этот показатель похож на предыдущий, но вместо измерения среднего времени, в течение которого открыт запрос на внесение изменений, он показывает среднее количество комментариев к каждому запросу. Опять же, не нужно, чтобы он был слишком высоким. Если кто-то получает по 12 комментариев каждый раз, когда вносит запрос на внесение изменений, это указывает на некоторые личные проблемы в команде. Но он не должен быть и слишком низким. Если каждый запрос получает один или ноль комментариев, на самом деле никто его и не смотрит. Используйте этот показатель таким же образом и в контексте, как и предыдущий. Ваша DVCS должна рассчитать и показать его вам автоматически.
3.4. Добавления и удаления кода (Code additions and deletions)
Ваша DVCS должна содержать график, который показывает изменения в коде (добавления и удаления) с течением времени, обычно измеряемые в CLOC (количество строк кода или количество измененных строк кода). Хорошо, если вы будете просматривать этот показатель регулярно. Вы должны не только смотреть на частоту и количество, но также искать закономерности. Много всплесков по выходным? Видимо, люди работают сверхурочно, что обычно является плохим знаком. Много добавлений, но нет удалений? Это говорит о том, что никто не занимается рефакторингом (поскольку рефакторинг обычно приводит к чистому уменьшению количества строк кода в системе, что хорошо). Помните, что исходный код является обязательством, а не активом. Идеальная система имеет ноль строк кода, а не миллионы.
4. Показатели непрерывной интеграции и развертывания ПО (CI and CD Tools)
Эти показатели содержатся в ваших инструментах непрерывной интеграции и развертывания (поставки). В настоящее время они, как правило, являются частью целостного инструментария DevOps и автоматизированного процесса поставки ПО.
4.1. Тестовое покрытие (Test coverage)
Это популярный и противоречивый показатель, на котором застревают многие люди. Это доля кода, которая покрывается автоматическими тестами. Более конкретно, это доля методов, для которых определены один или несколько автоматических тестов. Хотя автоматическое покрытие кода тестами – это хорошая идея, вам следует быть осторожным с этим показателем. Есть несколько причин для того, чтобы слишком полагаться на этот показатель:
- Он не различает хорошие и плохие тесты.
- Он не мешает разработчикам проводить абсолютно бесполезные тесты (просто назначая True в тесте).
- Он (обычно) не охватывает сквозные тесты, так как это не тестирование метода, а точки входа и компонентов пользовательского интерфейса системы.
Высокий показатель тестового покрытия – не обязательно хорошо. Если вы слишком сфокусированы на этом показателе и заставляете разработчиков его увеличивать, вы можете поощрять плохое поведение, так как они могут создать бесполезные тесты для улучшения показателей. Это плохо по двум причинам. Во-первых, это дает вам неправильное представление о вашем реальном тестовом покрытии. А во-вторых, это бесполезное и удручающее занятие для разработчиков.
Это не значит, что не нужно заботиться об автоматизации тестирования. Важно помнить, что ваше тестовое покрытие является сложной и нюансированной задачей, которую нельзя выразить одним простым числом. Оно должно быть частью регулярных обсуждений, подкрепленных некоторыми данными и регулярными проверками кода.
Краткое замечание:
Этот показатель на самом деле можно использовать без инструментов непрерывного развертывания CI/CD, поскольку он может быть определен путем анализа системы контроля версий (существует множество плагинов и инструментов, которые могут его рассчитать). Я, однако, поместил его в этот раздел, потому что он концептуально тесно связан с другими показателями CI/CD.
4.2. Коэффициент неудачных сборок (Good versus failed builds)
Это доля провальных сборок к общему числу сборок. Это должно быть небольшое число, в идеале очень маленькое. Разработчики должны запускать сборки на своем компьютере (на котором должна быть регулярно обновляемая кодовая база), прежде чем что-либо проверять. Если показатель превышает 5%, это плохой признак.
4.3. Пропущенные дефекты (Escaped defects)
Это количество дефектов, которые обнаруживаются только после того, как ПО поступило в эксплуатацию (production). Дефект может быть запущен в эксплуатацию, но его не следует рассматривать как инцидент (он может не повлиять на клиентов, но все же является дефектом). Также инцидент может возникнуть без дефекта (например, временный сбой инфраструктуры). Дефект – это проблема в кодовой базе. Количество пропущенных дефектов должно стремиться к нулю.
4.4. Неудачные развертывания (Unsuccessful Deployments)
Это просто количество неудачных развертываний. Вы можете подсчитывать их за неделю, месяц или год, в зависимости от того, как часто вы делаете релизы. Развертывание может быть неудачным по ряду причин, обычно из-за ошибок в конфигурации средства развертывания. Вы можете рассчитывать этот показатель только для эксплуатации или включить промежуточную (staging) или тестовую (testing) среду. Это показатель должен стремиться к нулю, особенно для эксплуатации. Вы сможете без труда получить этот показатель из своего инструмента DevOps.
4.5. Среднее время между релизами (Mean time between releases)
Этот показатель кажется очень простым, но вы должны помнить следующее:
- Вы должны считать только развертывания в эксплуатации. Промежуточная и тестовая среды не учитываются. Конечно, вы должны очень часто делать релизы в тестовой среде (несколько раз в день). Если вы этого не делаете, у вас есть более глубокая проблема.
- Вы должны считать только успешные релизы. Неудачные развертывания не учитываются (см. этот показатель выше).
- Это ПО не должно быть релизом для клиентов; это может быть пилотный релиз или удаленный доступ, отключение функций и т. д. Решение о релизе для клиентов – это другое решение (и оно в основном бизнес-, а не техническое решение).
Как измерить этот показатель
Это простой для измерения показатель: взять количество развертываний за определенный интервал времени (например, за три месяца) и разделить его на количество периодов времени (например, количество дней в трех месяцах). Это ваше среднее время между релизами. Вы можете выбрать любой период времени, который вам нравится, но вот несколько советов:
- Больший диапазон времени, как правило, дает лучшую выборку. Три месяца, вероятно, хорошая отправная точка, но вы можете изменить его, если для вас это имеет смысл.
- Используйте скользящий диапазон времени: если вы выбрали три месяца, не смотрите среднее значение раз в три месяца, смотрите среднее значение каждый месяц за последние три месяца.
- Не изменяйте произвольно размер выборки по времени, чтобы улучшить статистику, какая бы она ни была. Будьте честны и прозрачны.
4.6. CLOC на релиз (CLOC per release)
Напомню, CLOC – это количество измененных строк кода. Это измерение среднего числа строк измененного кода на один релиз ПО. Измененная строка означает удаленную строку, добавленную строку или измененную строку: все они считаются как одна измененная строка. Таким образом, чтобы вычислить этот показатель, вы делите общее количество измененных строк кода в данной серии релизов на количество релизов за этот период. Это может показаться нелогичным, но желательно, чтобы этот показатель был низким и становился все ниже. Это связано с тем, что в небольших релизах меньше изменений, меньше сложностей и меньше рисков. Множество небольших релизов гораздо предпочтительнее, чем один большой.
5. Показатели инструментов бизнес-аналитики (Business Intelligence Tools)
Возможно, кто-то удивится, увидев здесь эти показатели. Это же абстрактные показатели, относящиеся к «бизнесу», а команда разработчиков программного обеспечения должна сфокусироваться на практических показателях, вроде скорости и количества дефектов. А бизнес-аналитика – это просто мусор для менеджеров! Нет, на самом деле, это ваши важнейшие показатели. Это ваша ценность, а не ваш продукт. И вся команда должна знать и думать об этих показателях. Я достиг наибольших успехов с командами разработчиков программного обеспечения, когда вся команда испытывала чувство гордости и ответственности за то, что они создают. Они чувствуют связь с клиентами, ценностью, которую они предоставляют, и результатами для бизнеса, которые они обеспечивают.
Я разделил содержание этого раздела согласно «пиратским показателям» или AARRR (потому что так говорят в кино пираты: «Aarrr!»). Это означает: привлечение, активация, удержание, рекомендация и доход (Acquisition, Activation, Retention, Referral, Revenue).
Привлечение (Acquisition)
5.1. Уникальные посетители (Unique visitors)
Это общий показатель, используемый для отслеживания того, как люди заходят на ваш сайт. Убедитесь, что посетители уникальны (обычно это делается путем удаления дубликатов по IP-адресу). Этот показатель находится наверху пиратской «воронки» продаж (т.е. это самое широкое место воронки и самое большое число посетителей в воронке, и остальные показатели часто выражаются в процентах от уникальных посетителей). Убедитесь, что вы не уделяете слишком много внимания уникальным посетителям. Некоторые люди называют его «показателем тщеславия»: это большое число, и на нем часто делают акцент, чтобы произвести впечатление на потенциальных инвесторов или средства массовой информации. Но если вы продаете доступ к сайту за плату, и немногие из уникальных посетителей его покупают, то этот показатель не очень значим для вашего бизнеса. Если этот показатель очень маленький, то, вероятно, вам следует приложить некоторые усилия по продвижению сайта, но как только он начнет расти, лучше обратить свое внимание и усилия на другие показатели.
Активация (Activation)
5.2. Коэффициент конверсии (Conversion rate)
Коэффициент конверсии часто используется в различных контекстах. Его часто измеряют в разных точках путешествия по воронке: конверсия (преобразование) посетителей веб-сайта в подписчиков или потенциальных клиентов сайта (это контекст, о котором я здесь говорю), конверсия потенциальных клиентов в «пробных» клиентов (которые используют бесплатные пробные версии), преобразование пробных клиентов в платящих клиентов и т.д. Но концепция в целом одинакова на каждом этапе: какая доля клиентов с более высокой ступени воронки переходит ниже, выражается обычно в процентах. Поэтому, если у вас есть 10000 уникальных посетителей веб-сайта в месяц, и 2000 из них подписываются на вашу рассылку, или загружают ваш документ, или делают что-то еще, тогда ваш коэффициент конверсии составляет 20%.
Удержание (Retention)
5.3. Ежемесячные активные пользователи (Monthly Active Users)
Ежемесячные активные пользователи – это очень распространенный показатель, особенно для социальных сетей или поставщиков услуг SAAS (Software As A Service). Это всего лишь показатель того, сколько пользователей взаимодействовали с вашим веб-сайтом или приложением, или использовали ваш продукт SaaS за месяц. Некоторые говорят, что MAU – это «источник жизненной силы» приложения или SaaS-бизнеса. Я отнес этот показатель к разделу «удержание», поскольку он указывает не на то, сколько людей заходят на ваш продукт, а на то, сколько людей его придерживаются. Обратите внимание, что эти MAU могут вам платить или нет, в зависимости от модели ценообразования вашего сервиса. У некоторых поставщиков есть бесплатная пробная версия, у других есть урезанная бесплатная версия и полная платная версия, у некоторых есть только платная версия.
5.4. Доход (Revenue)
Существуют разные модели ценообразования и, следовательно, модели получения дохода, поэтому мне трудно выбрать, какие показатели здесь рассмотреть. Вероятно, у вас могут быть другие показатели, подходящие для вашего бизнеса и модели ценообразования. Я попытался включить самые популярные, которые вы, скорее всего, сможете использовать.
5.5. Коэффициент конверсии (Conversion rate)
Ранее мы уже рассматривали коэффициент конверсии как показатель активации. Там говорилось о проценте людей на входе вашей воронки (например, посетителей вашего сайта, страницы магазина приложений и т.д.), которые переходят на этап Активации: они подписываются на пробную версию ПО или на новостную рассылку и т. д. Здесь коэффициент конверсии относится к проценту людей, которые уже достигли стадии активации воронки и затем стали вашими платящими клиентами. Этот способ оплаты, конечно, будет зависеть от вашей конкретной модели ценообразования (разовая, абонентская – ежемесячная или ежегодная, или что-то еще). Он также выражается в процентах и рассчитывается как количество доходных клиентов, деленное на количество активированных посетителей, умноженное на 100).
5.6. Ежемесячный регулярный доход (Monthly recurring revenue)
Этот показатель (часто сокращенно называемый MRR) является еще одной классикой бизнеса SaaS. Это просто число ваших ежемесячных пользователей (MAU), умноженное на сумму их оплаты. Если у вас есть разные уровни ценообразования, то вам придется разбить их на отдельные MAU и умножить на их соответствующие уровни ценообразования (или взвесить доход на пользователя на долю вашей пользовательской базы на этом уровне ценообразования). Так что, если 30% ваших пользователей платят 20 долларов в месяц, а 70% платят 50 долларов в месяц, тогда ваш взвешенный доход на пользователя составляет 0,3 * 20 + 0,7 * 50 = 41. Умножьте это на ваше количество пользователей, и вы получите MRR.
5.7. Проход (Throughput)
Проход – это концепция из Теории ограничений Эли Голдратта. Если вы хотите разобраться в деталях, я бы порекомендовал вам прочитать его роман «Цель». Проще говоря, проход – это чистый объем продаж. [Точнее, Проход = Доход минус полностью переменные затраты. Нужно быть осторожными с определением того, что включать в полностью переменные затраты.] Этот показатель проще понять в контексте производства или розничной торговли, где существуют четкие затраты на единицу продукта (стоимость сырья для производства единицы продукта или цена закупа для товаров, проданных в розницу).
Важный момент заключается в том, что в учете прохода не используется концепция себестоимости, не пытаются распределить все затраты на единицу продукта (что обычно пытаются делать большинство методологий учета затрат, таких как учет затрат по отдельным видам деятельности (ABC – Activity Based Costing). Продажа программного обеспечения на самом деле не имеет понятия цены за проданную единицу (программное обеспечение практически ничего не стоит для массового производства или распространения, особенно с отказом от распространения на физических носителях).
В Учете прохода заложен глубочайший сдвиг мышления, который трудно объяснить в рамках этой статьи и без сравнения с традиционными методами учета.
5.8. Стоимость задержки (Cost of Delay)
Этот показатель, по мнению некоторых людей (например, Дональда Рейнертсена), является важнейшим показателем, особенно в контексте разработки ПО (и разработки программного обеспечения по Agile). Он показывает, какой доход вы теряете из-за отказа от выпуска вашего продукта в течение определенного периода времени. Например, если вы могли бы выпустить свое программное обеспечение сегодня и заработать 1000 долларов в течение следующего месяца, то выпустив ПО вместо этого через месяц, вы упускаете эту 1000 долларов дохода. Таким образом, ваша стоимость задержки на этот месяц составляет $ 1000. Оценка потерянного дохода может быть сложной и сильно зависеть от вашего конкретного продукта и обстоятельств, поэтому я не могу дать здесь точное руководство.
Райнертсен в своей книге «The Principles of Product Development Flow» пишет, что многие решения относительно приоритета работы или ресурсов могут и должны быть преобразованы в стоимость задержки, чтобы получить простой ответ. Всегда помните, что этот показатель должен рассчитываться за период времени: неделя, месяц и т.д. По этой причине некоторые люди иногда используют «Стоимость задержки, деленную на продолжительность» в качестве входных данных в методе определения приоритетов, который называется «Сначала самая короткая задача» (Weighted Shortest Job First).
Рекомендация (Referral)
5.9. Показатель лояльности клиентов (Net Promoter Score – NPS)
Этот важный бизнес-показатель демонстрирует, насколько ваши клиенты готовы рекомендовать вас другим людям. Это число колеблется от -100 (вероятно, ни один из клиентов не будет рекомендовать вас другим) до 100 (вероятно, каждый ваш клиент будет рекомендовать вас другим). Расчет не так прост. Во-первых, вы должны провести опрос среди своих клиентов: «Оцените по шкале от 0 до 10 вероятность того, что вы порекомендуете наши продукты или услуги своим друзьям или коллегам?». Затем разделите по ответам клиентов на «Сторонников» (промоутеров), которые дают оценку 9 или 10, «Нейтральных» (оценка 7 или 8), и «Критиков» (детракторов), выставляющих 6 или ниже. Затем рассчитайте процент промоутеров и критиков. Наконец, вычтите процент критиков из процента промоутеров. Таким образом, если 50% ваших респондентов являются промоутерами, а 30% – критиками, ваш NPS равен 20 (50 минус 30).
NPS считается очень важным для общего роста и успеха бизнеса. Трудно доказать строгие причинно-следственные связи, потому что NPS основан на ответах опроса, которые могут не указывать на фактическое поведение (а многие рефералы являются сарафанным радио, и поэтому их невозможно отследить или доказать). Вы может игнорировать этот показатель на свой страх и риск. Но исследования показали, что NPS является очень сильным предиктором успешного бизнеса.
5.10. Коэффициент успешности рекомендаций (Referral Success Rate)
Вы можете поддержать свой продукт или услугу реальной системой рекомендаций, предлагая клиентам бонус или скидку в обмен на рекомендацию вашей компании другим людям. Это можно сделать различными способами, например, скидка за приведенного друга, бесплатный месяц тому, кто поделится рекламой компании на Facebook, и так далее. Коэффициент успешности рекомендаций – это процент рекомендаций, которые заканчиваются продажей. Вы также можете отдельно отследить долю клиентов, решивших принять участие в программе рекомендаций (хотя это лишь показатель тщеславия, поскольку, если потенциальные клиенты не принимают рекомендованное предложение и не превращаются в клиентов, на самом деле не имеет значения, сколько людей вас рекомендует).
Заключение
Я надеюсь, вам понравилось это долгое путешествие в мир Agile показателей. Я надеюсь, что рассмотрел все важные показатели, которые вам могли бы пригодиться. Пожалуйста, помните, что их следует выбирать и использовать с умом. Помните, Альберт Эйнштейн говорил: «Не все, что можно сосчитать, считается, и не все, что считается, можно сосчитать».
Автор: Leon Tranter
Источник: https://tocpeople.com/
Понравилась статья? Тогда поддержите нас, поделитесь с друзьями и заглядывайте по рекламным ссылкам!