
 Иллюстрация: Zijun Chen et al. / Nature. Физики недавно разработали абсолютно новый метод уменьшения количества кубитов, необходимых для эффективной коррекции всех ошибок в квантовых вычислителях. В работе, которая опубликована в известном журнале Nature, ученые разработали код коррекции ошибок, обеспечивающий экспоненциальное снижение шума в зависимости от числа используемых кубитов. Авторы исследования также провели детальный анализ различных типов ошибок, возникающих в квантовых вычислениях. Коррекция ошибок является ключевым фактором для успешной реализации квантовых компьютеров. Полностью устранить шум в реальных системах невозможно, поэтому разработка эффективных методов его безусловной коррекции приобретает первостепенное значение. Основная сложность создания кодов коррекции ошибок заключается в необходимости балансирования между количеством кубитов, задействованных в процессе коррекции, и вероятностью возникновения ошибок.
Иллюстрация: Zijun Chen et al. / Nature. Физики недавно разработали абсолютно новый метод уменьшения количества кубитов, необходимых для эффективной коррекции всех ошибок в квантовых вычислителях. В работе, которая опубликована в известном журнале Nature, ученые разработали код коррекции ошибок, обеспечивающий экспоненциальное снижение шума в зависимости от числа используемых кубитов. Авторы исследования также провели детальный анализ различных типов ошибок, возникающих в квантовых вычислениях. Коррекция ошибок является ключевым фактором для успешной реализации квантовых компьютеров. Полностью устранить шум в реальных системах невозможно, поэтому разработка эффективных методов его безусловной коррекции приобретает первостепенное значение. Основная сложность создания кодов коррекции ошибок заключается в необходимости балансирования между количеством кубитов, задействованных в процессе коррекции, и вероятностью возникновения ошибок.
Для реализации одного логического кубита требуется использовать несколько физических кубитов: один несет основную информацию, а остальные служат для мониторинга и обнаружения ошибок.
Предложенный код коррекции ошибок позволяет эффективно снизить количество необходимых кубитов, что существенно упрощает проектирование и реализацию квантовых вычислительных систем.
Понятно, что сто физических кубитов в качестве одного логического позволят очень точно отслеживать и исправлять ошибки, но такой подход только добавляет сложностей в создании экспериментального устройства. Поэтому хороший метод коррекции ошибок не просто должен снижать шум, но и делать это с помощью наименьшего числа вспомогательных кубитов.

Ученые из Google AI во главе с Джулианом Келли (Julian Kelly) показали, что уровень ошибок может падать экспоненциально с увеличением числа кубитов. Они разработали код, для которого возникает такая зависимость, сравнили его с поверхностным кодом для квантовой коррекции ошибок и подробно изучили вклады разных типов ошибок.
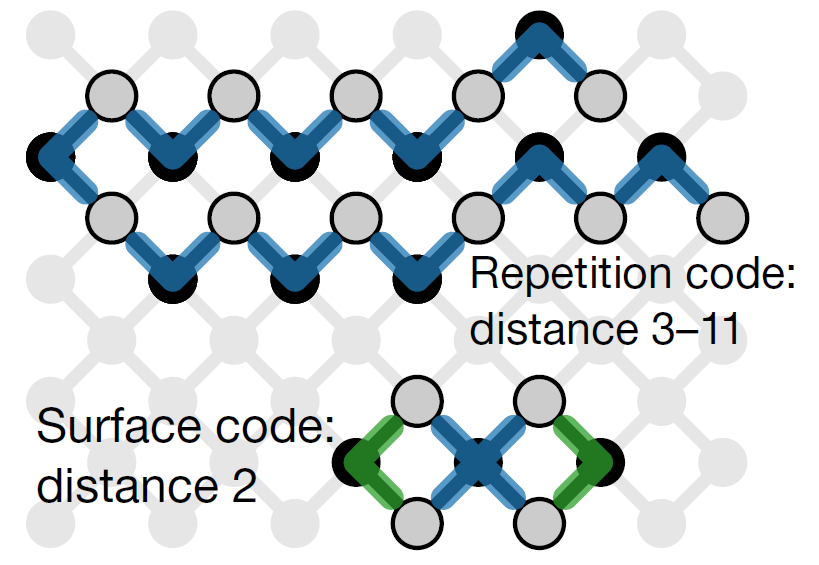
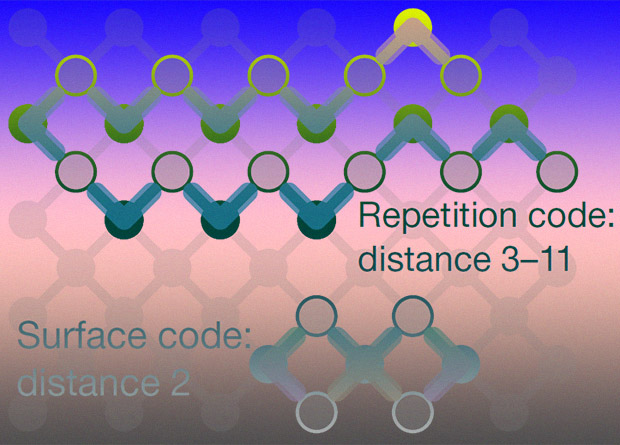
Различие между повторяющимися и поверхностными кодами. Zijun Chen et al. / Nature
Для моделирования и экспериментов физики использовали 54-кубитной сверхпроводящий вычислитель Sycamore, известный благодаря статье о квантовом превосходстве. Он представляет собой двумерную матрицу кубитов, каждый из которых связан с четырьмя соседями и позволяет реализовывать два типа кодов коррекции ошибок: код с повторением и поверхностный. Работа первого использует цепочку из физических кубитов и получается, что на каждый информативный кубит есть два соседа, которые следят за ошибками, а второй «расползается» по поверхности и на каждый кубит приходится по 4 следящих соседа. Так как ошибки могут возникать не только в самом кубите, но и в операциях (вентилях), которым он подвергается, то поверхностный код кажется эффективнее — в отличие от кода-цепочки он может контролировать более сложные двухкубитные операции. Помимо этого, как можно догадаться, код с повторением требует повторения фиксированного набора итераций, а время жизни кубита ограничено. С другой, для поверхностного кода нужно большее число кубитов, что на данный момент непросто.
Авторы применяли первый тип коррекции ошибок для цепочки из 21 кубита (11 информативных) и смогли получить заданное состояние кубитов с ошибкой около 0.5 процентов и откалибровать систему так, чтобы уровень ошибки в операции CZ (контролируемый Z-вентиль) оказался 0.62 процента. Кроме этого, процент ошибок оказался стабильным — он не менялся в течение 50 циклов коррекции.
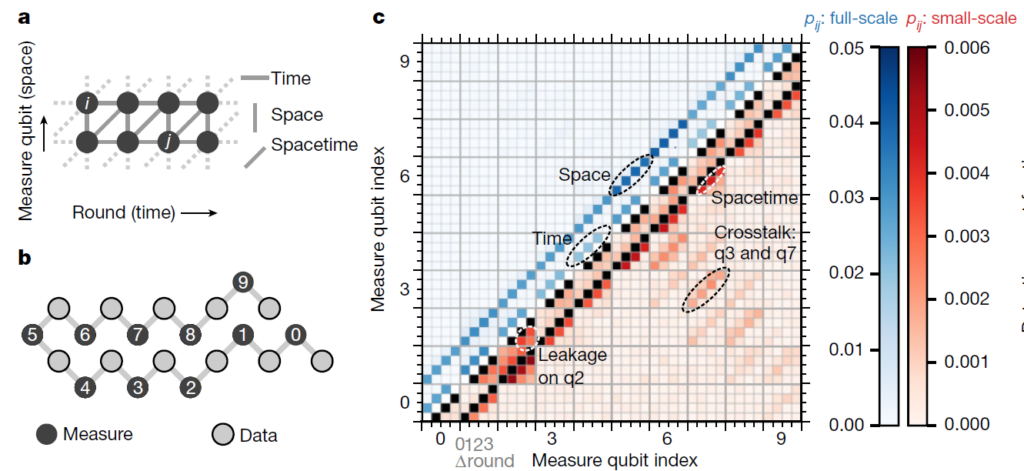
Разные виды ошибок (a), нумерация кубитов (b) и корреляции между ними, свойственные разным типам ошибок. Zijun Chen et al. / Nature
В повторяющихся кодах можно выделить три типа самых распространенных ошибок — пространственная, временная и пространственно-временная. Индикатор первой — ошибка в одном и том же цикле в двух кубитах-соседях к информативному, вторая возникает в разных временных циклах, а третья — комбинация первых двух. Для того чтобы оценить влияние каждой из них и проверить наличие других неучтенных ошибок, ученые следили за корреляциями между всеми измеряемыми кубитами в цепочке. В идеальной цепочке без ошибок и возможных связей между кубитами корреляции не должно быть. Наличие корреляций в соседних по времени и пространству кубитах говорит об ошибках в вычислителе. Как оказалось, именно эти два типа ошибок вносят основной вклад, в то время как пространственно-временная встречается почти в десять раз реже, как и еще два других типа ошибок. Первый связан с тем, что цепочка не расположена вдоль одной прямой, а загибается, поэтому некоторые кубиты оказываются рядом, хоть и различаются номерами больше чем на 1. А второй возникает между разными циклами и, по мнению физиков, связан с применением вентилей и термализацией.
Для того чтобы показать преимущество исследуемого кода, авторы получили зависимость итогового процента ошибок от числа кубитов. Эта зависимость оказалась экспоненциальной (быстро спадает), то есть при увеличении числа кубитов от 5 до 21 вероятность ошибки падает в 100 раз. Экспериментальная проверка одномерного и двумерного поверхностного кодов коррекции подтвердила результаты моделирования и показала, что архитектура Sycamore имеет процент ошибок значительно меньший, чем пороговое значения для поверхностного кода.
Несмотря на то, что авторам удалось показать быстрое спадание уровня ошибок при увеличении числа кубитов для разработанного кода и выявить ошибки, которые вносят наибольший вклад, для реальных устройств этого пока еще недостаточно. Поэтому ученые планируют дальнейшие исследования для нивелирования ошибок и механизмов их возникновения.
Физики исследуют и другие типы кодов для коррекции ошибок: изначально в Google использовали торический код для матрицы 7 на 7, а домашнее задание студента из университета Сиднея вылилось в разработку эффективного поверхностного кода.
Автор: Оксана Борзенкова
Источник: https://nplus1.ru/
