

Только подумайте, какова совокупная вычислительная мощность всех смартфонов в мире? Это огромнейший вычислительный ресурс, который вполне может эмулировать даже работу человеческого мозга. Нельзя, чтобы такой ресурс простаивал без дела, тупо прожигая киловатты энергии на чатики и ленты социальных сетей. Если отдать эти вычислительные ресурсы единому распределённому мировому ИИ, да ещё снабдить его данными с пользовательских смартфонов — для обучения — то такая система может осуществить качественный скачок в данной области. Стандартные методы машинного обучения требуют, чтобы набор данных для обучения модели («первичка») был собран в одном месте — на одном компьютере, сервере или в одном дата-центре или облаке.

Отсюда его забирает модель, которая проходит обучение на этих данных. В случае с кластером компьютеров в дата-центре применяется метод стохастичного градиента (Stochastic Gradient Descent, SGD) — алгоритм оптимизации, который постоянно проходит по частям набор данных, гомогенно распределённый по серверам в облаке.

Компании Google, Apple, Facebook, Microsoft и остальные игроки в сфере ИИ давно занимаются именно этим: собирают данные — иногда конфиденциальные — с компьютеров и смартфонов пользователей в единое (предположительно) защищённое хранилище, на котором тренируют свои нейросети.
Сейчас учёные из Google Research предложили интересное дополнение к этому стандартному методу машинного обучения. Они предложили инновационный подход под названием федеративное машинное обучение (Federated Learning). Он позволяет всем устройствам, которые участвуют в машинном обучении, делить на всех единую модель для прогнозирования, но при этом не делиться первичными данными для обучения модели!
Такой необычный подход, может быть, и снижает эффективность машинного обучения (хотя это ещё не факт), но зато существенно снижает затраты Google на содержание дата-центров. Зачем компании вкладывать огромные суммы в своё оборудование, если у неё во всём мире есть миллиарды Android-устройств, которые могут разделить нагрузку между собой? Пользователи могут быть рады такой нагрузке, ведь они тем самым помогают сделать лучше сервисы, которыми сами пользуются. А ещё защищают свои конфиденциальные данные, не отправляя их в дата-центр.
Google подчёркивает, что в данном случае речь идёт не просто о том, что уже обученная модель выполняется непосредственно на устройстве пользователя, как это происходит в сервисах Mobile Vision API и On-Device Smart Reply. Нет, именно обучение модели осуществляется на конечных устройствах.
Система федеративного обучения работает по стандартному принципу распределённых вычислений типа SETI@Home, когда миллионы компьютеров решают одну большую сложную задачу. В случае SETI@Home это был поиск аномалий в радиосигнале из космоса по всей ширине спектра. А в случае федеративного машинного обучения Google это совершенствование единой общей модели (пока) слабого ИИ. На практике цикл обучения реализован следующим образом:
- смартфон скачивает текущую модель;
- с помощью мини-версии TensorFlow осуществляет цикл обучения на уникальных данных конкретного пользователя;
- улучшает модель;
- вычисляет разницу между улучшенной исходной моделями, составляет патч с применением криптопротокола Secure Aggregation, который допускает расшифровку данных только при наличии сотен или тысяч патчей от других пользователей;
- отправляет патч на центральный сервер;
- принятый патч немедленно усредняется с тысячами патчей, полученных от других участников эксперимента, по алгоритму федеративного усреднения;
- выкатывается новая версия модели;
- улучшенная модель рассылается участникам эксперимента.
Федеративное усреднение очень похоже на вышеупомянутый метод стохастичного градиента, только здесь первоначальные вычисления происходят не на серверах в облаке, а на миллионах удалённых смартфонов. Основное достижения федеративного усреднения — в 10-100 раз меньший трафик с клиентами, чем трафик с серверами при использовании метода стохастичного градиента. Оптимизация достигнута за счёт качественного сжатия апдейтов, которые отправляются со смартфонов на сервер. Ну и плюс здесь используется криптографический протокол Secure Aggregation.
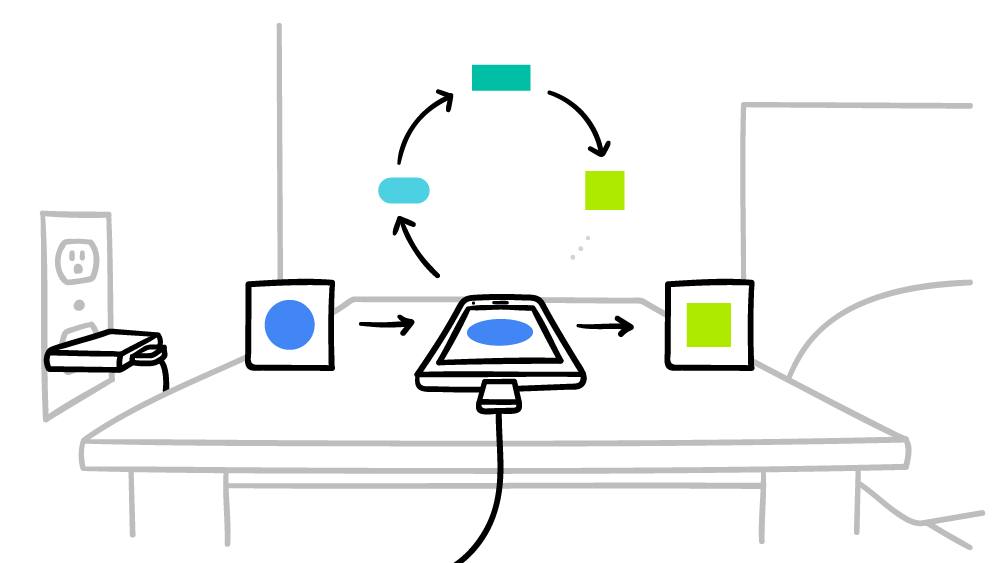
Google обещает, что смартфон будет производить вычисления для распределённой мировой системы ИИ только в моменты простоя, так что это никак не скажется на производительности. Более того, можно установить время работы только на время, когда смартфон подключен к электросети. Таким образом, эти расчёты даже не повлияют на время работы от аккумулятора. В данный момент федеративное машинное обучение уже тестируют на контекстных подсказках в клавиатуре Google — Gboard on Android.
Более подробно алгоритм федеративного усреднения данных (Federated Averaging) описан в научной работе Communication-Efficient Learning of Deep Networks from Decentralized Data, которая опубликована 17 февраля 2016 года на arXiv.org (arXiv:1602.05629).
Автор: Анатолий Ализар @alizar
Источник: https://habr.com/
