
 Несколько лет назад мы решили, что предсказание наводнений даёт уникальную возможность улучшить жизни людей, и начали смотреть, как инфраструктура и опыт в машинном обучении компании Google может помочь в этой области. В прошлом году мы начали наш пилотный проект по предсказанию наводнений в индийском регионе Патна, и с тех пор расширили покрытие предсказания в рамках политики «ИИ на социальное благо». В данной статье мы обсуждаем некоторые технологии и методологии, стоящие за этими попытками. Критический шаг в разработке точной системы предсказания наводнений – разработать модели наводнений, использующие либо измерения, либо предсказания уровня воды в реке в качестве входных данных, и симулирующие поведение воды в её пойме. Это позволяет нам превратить текущее или будущее состояние реки в чрезвычайно точные пространственные карты риска, говорящие нам, какие области будут залиты водой, а какие останутся безопасными. Модели наводнений зависят от четырёх основных компонентов, у каждого из которых есть свои сложности и инновации:
Несколько лет назад мы решили, что предсказание наводнений даёт уникальную возможность улучшить жизни людей, и начали смотреть, как инфраструктура и опыт в машинном обучении компании Google может помочь в этой области. В прошлом году мы начали наш пилотный проект по предсказанию наводнений в индийском регионе Патна, и с тех пор расширили покрытие предсказания в рамках политики «ИИ на социальное благо». В данной статье мы обсуждаем некоторые технологии и методологии, стоящие за этими попытками. Критический шаг в разработке точной системы предсказания наводнений – разработать модели наводнений, использующие либо измерения, либо предсказания уровня воды в реке в качестве входных данных, и симулирующие поведение воды в её пойме. Это позволяет нам превратить текущее или будущее состояние реки в чрезвычайно точные пространственные карты риска, говорящие нам, какие области будут залиты водой, а какие останутся безопасными. Модели наводнений зависят от четырёх основных компонентов, у каждого из которых есть свои сложности и инновации:

Трёхмерная визуализация гидравлической модели, симулирующей различные состояния реки
Измерение уровня воды в реальном времени
Чтобы запускать эти модели с пользой, нам нужно знать, что происходит на земле в реальном времени – поэтому мы полагаемся на то, что наши партнёры из соответствующих правительственных учреждений смогут вовремя передавать нам точную информацию. Первым нашим правительственным партнёром стала центральная водная комиссия Индии (CWC), ежечасно измеряющая уровни воды в более чем тысяче русел рек по всей Индии, собирающая эти данные и выдающая прогнозы на основе измерений в верховьях рек. CWC предоставляет эти измерения в реальном времени и прогнозы, а потом они используются в качестве входящих данных для наших моделей.
 Сотрудники CWC измеряют уровень и расход воды близ Лакхнау
Сотрудники CWC измеряют уровень и расход воды близ Лакхнау
Создание карты высот
Узнав, сколько воды в реке, критически важно предоставить модели хорошую карту местности. Цифровые высотные модели высокого разрешения (DEM) невероятно полезны для широкого спектра применений в науках о Земле, но для большей части планеты пока недоступны, особенно для предсказания наводнений. Даже особенности метровых размеров могут привести к критической разнице результатов наводнения (одним из чрезвычайно важных примеров могут служить дамбы), но разрешение публично доступных DEM составляет десятки метров. Чтобы побороть эту проблему, мы разработали новую методологию, выдающую DEM высокого разрешения на основе совершенно обычных оптических фотографий.

Начинаем мы с большой и разнообразной коллекции спутниковых изображений, используемых в Google Maps. Сопоставляя и выравнивая изображения большими пакетами, мы одновременно проводим коррекцию как неточностей спутниковой камеры (ошибки ориентации, и т.д.), так и данных по высотам. Затем мы используем скорректированные модели камеры для создания карты глубины для каждого изображения. Для получения карты высот мы оптимальным образом соединяем карты глубин для каждого участка. Наконец, мы убираем с них такие объекты, как деревья и мосты, чтобы те не блокировали водные потоки в симуляциях. Это можно делать вручную, или обучив свёрточную нейронную сеть разбираться, в каких местах нужно интерполировать высоты. В итоге получается DEM с разрешением примерно 1 м, которую можно использовать для запуска гидравлических моделей.
 DEM шириной в 30 м участка реки Джамна, и DEM того же самого участка с разрешением в 1 м, полученная Google
DEM шириной в 30 м участка реки Джамна, и DEM того же самого участка с разрешением в 1 м, полученная Google
Гидравлическое моделирование
Получив все эти входные данные – речные измерения, прогнозы и карту высот – мы можем начать сам процесс моделирования, который можно разделить на два основных компонента. Первый и наиболее важный – физическая гидравлическая модель, обновляющая местоположение и скорость воды во времени на основе примерных вычислений законов физики. В частности, мы реализовали решающую программу для уравнений двумерной мелкой воды (уравнений Сен-Венана). Эти модели достаточно точны при качественных входных данных и работе с высоким разрешением, но их вычислительная сложность создаёт проблемы, поскольку она пропорциональна кубу разрешения. При удвоении разрешения время вычислений вырастает примерно в 8 раз. А поскольку мы убеждены, что для точных прогнозов требуется большое разрешение, вычислительная стоимость этой модели может оказаться неприступной даже для Google!
Чтобы решить эту проблему, мы придумали уникальную реализацию нашей гидравлической модели, оптимизированную для Tensor Processing Units (TPU). Хотя TPU оптимизированы для нейросетей, а не для решения дифференциальных уравнений, их параллелизуемая природа даёт 85-кратный прирост скорости вычислений на ядре TPU по сравнению с ядром CPU. Дополнительная оптимизация достигается за счёт использования машинного обучения, помогающего заменить некоторые физические алгоритмы, и расширения дискретизации на основе данных на двумерные гидравлические модели, что позволяет нам поддерживать ещё большие по размеру сетки.
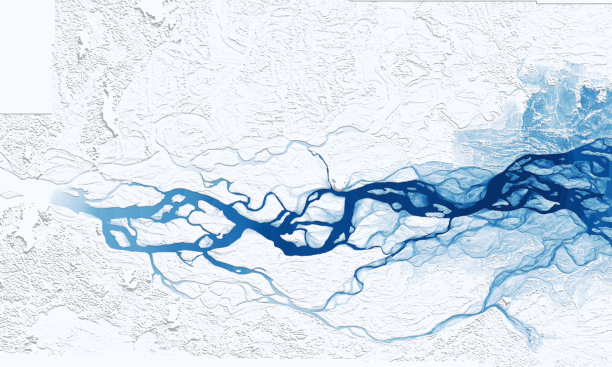 Эмуляция наводнения в Гоалпаре на TPU
Эмуляция наводнения в Гоалпаре на TPU
Как уже упоминалось, гидравлическая модель – это только один из компонентов наших прогнозов наводнений. Мы постоянно натыкались на участки, где наши гидравлические модели оказывались недостаточно точными – будь то из-за неточностей в DEM, прорывов в дамбах, или неожиданных источниках воды. Наша цель – найти эффективные способы уменьшить эти ошибки. Для этого мы добавили прогнозирующую модель наводнения, основанную на исторических измерениях. С 2014 года Европейское космическое агентство обладает набором спутников “Часовой-1“, использующих радары с радиолокационным синтезированием апертуры (РАС) в С-диапазоне. Изображения РАС отлично подходят для обнаружения наводнений, и их можно получать вне зависимости от облачности и погодных условий. На основе этого ценного набора данных мы сравниваем исторические измерения уровней воды с историческими наводнениями, что позволяет нам применять последовательные правки к нашим гидравлическим моделям. На основе выдачи обоих компонентов мы можем оценить, какие различия в них вызваны реальными изменениями состояния поверхности, а какие – неточностями модели.
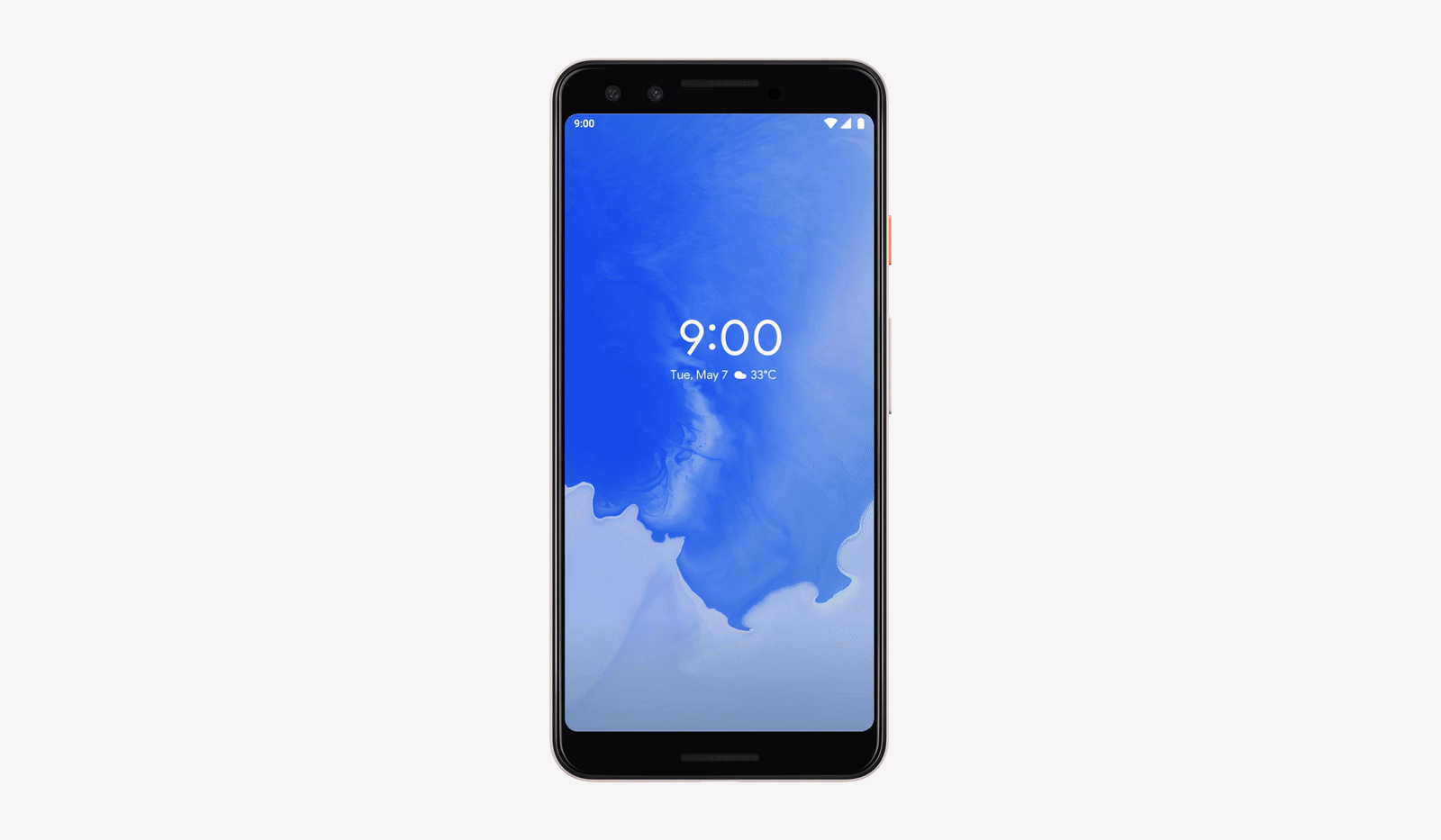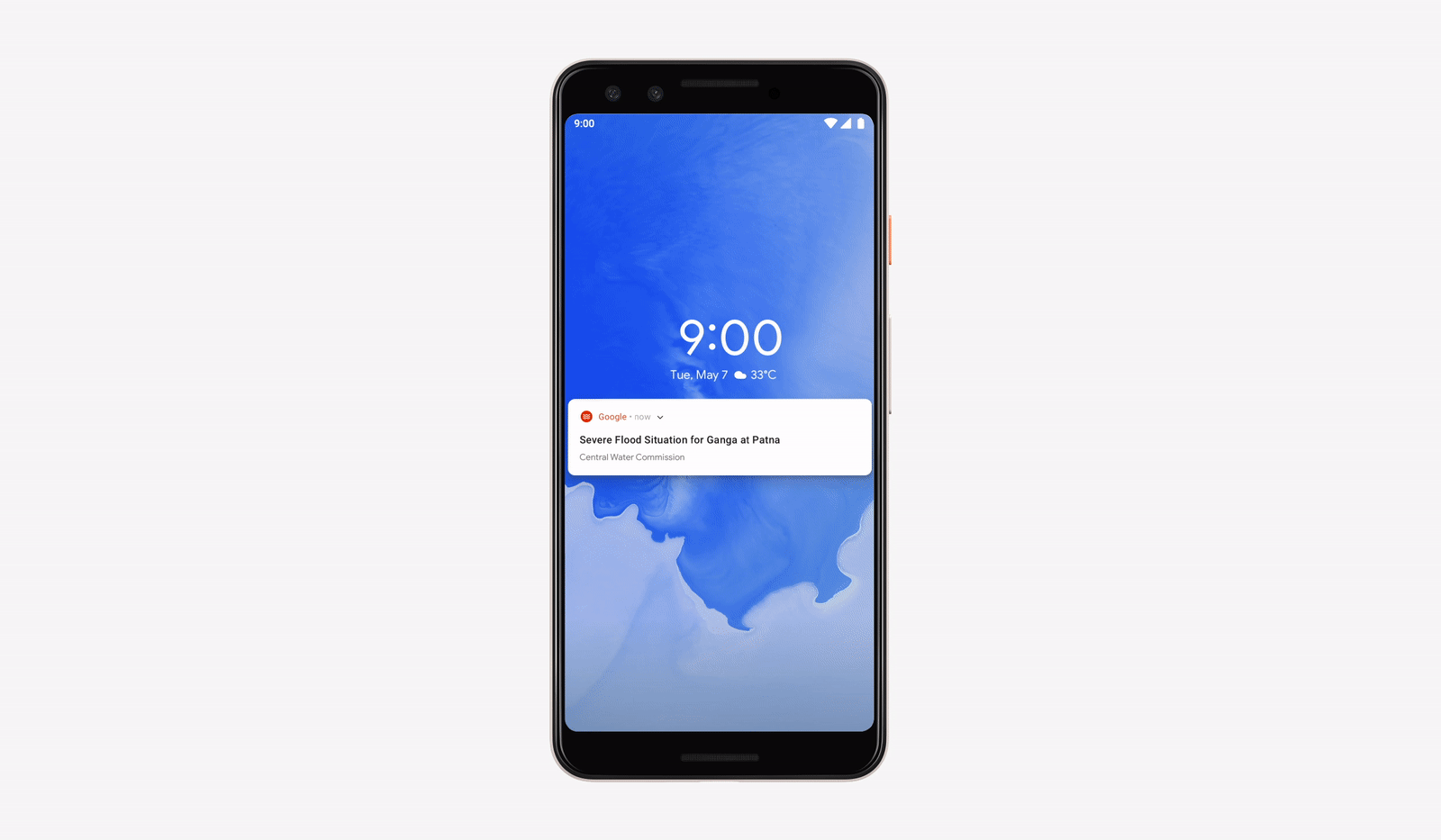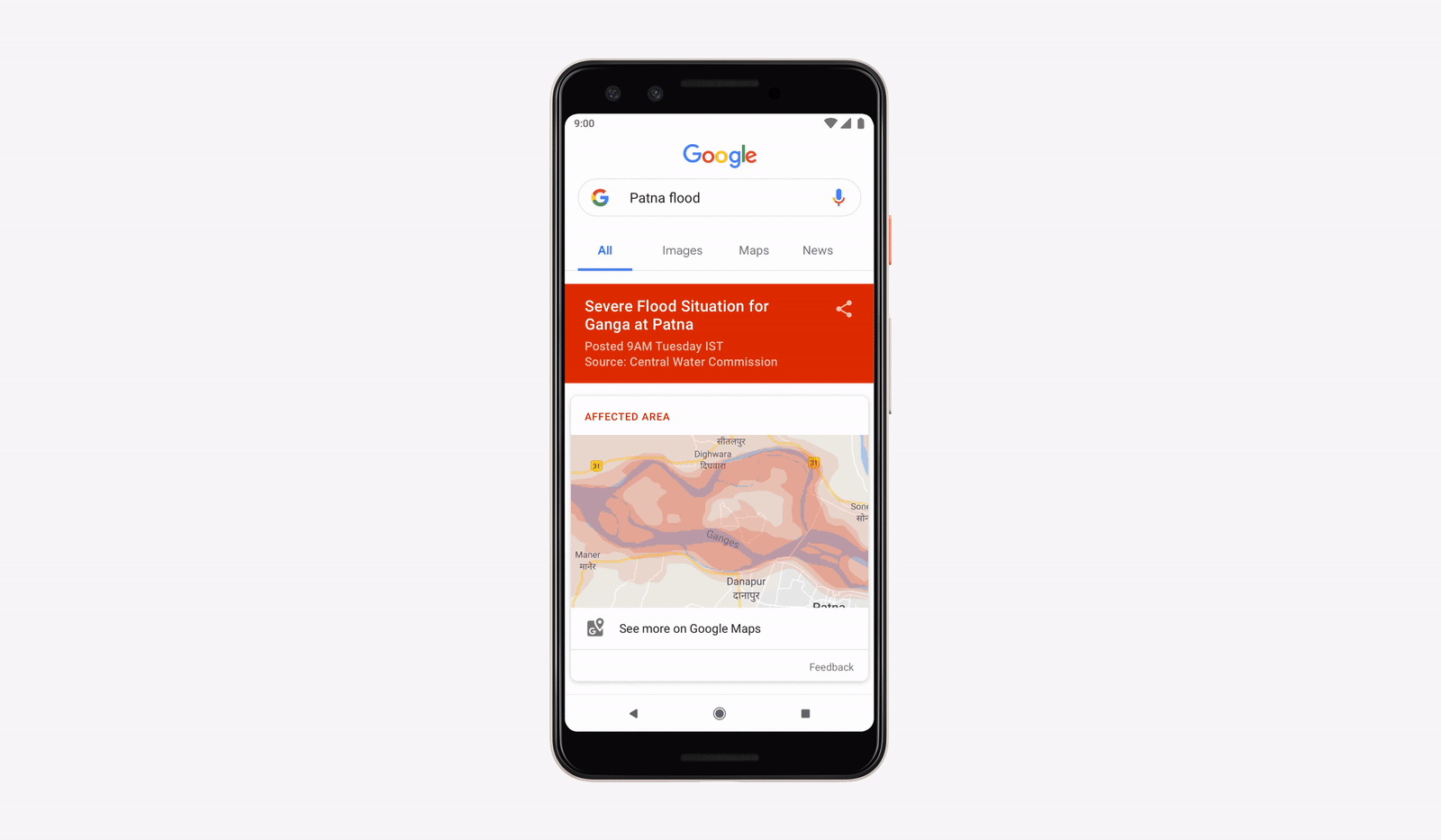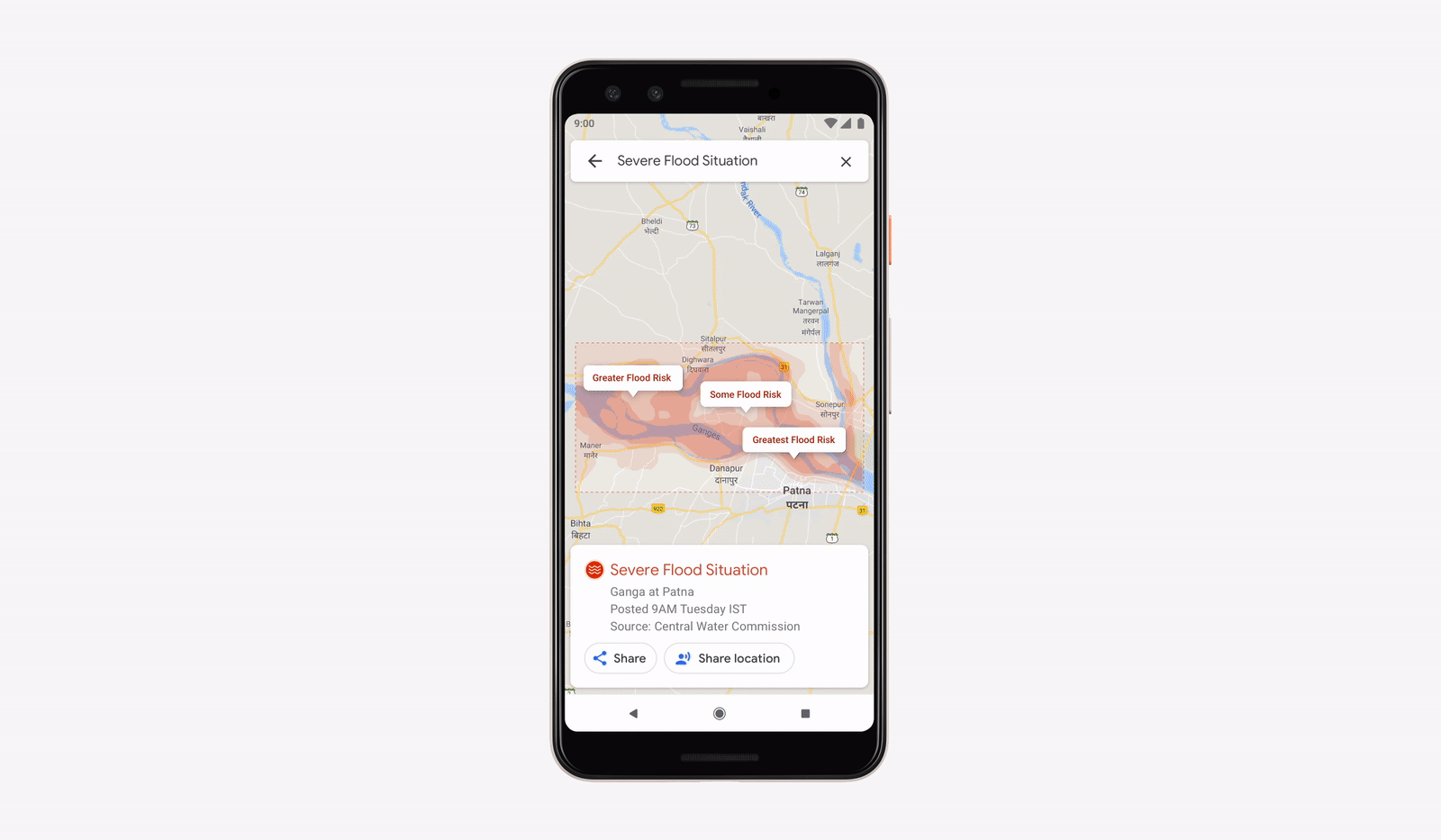 Предупреждения о наводнениях в интерфейсах Google
Предупреждения о наводнениях в интерфейсах Google
Планы на будущее
Нам ещё многое предстоит сделать, чтобы в полной мере понять преимущества наших моделей наводнений. В первую очередь мы работаем над расширением покрытия наших операционных систем, как в Индии, так и в других странах. Также мы хотели бы иметь возможность выдавать больше информации в реальном времени – предсказывать глубину наводнения, временную информацию, и прочее. Кроме того, мы исследуем вопрос того, как лучше всего будет передавать эту информацию отдельным людям с максимальной ясностью, поощряя их принимать предупредительные меры.
Хотя модели наводнения являются хорошими инструментами для улучшения пространственного разрешения (а, следовательно, точности и надёжности) существующих прогнозов наводнений, различные правительственные учреждения и международные организации, с которыми мы работали, беспокоятся о тех областях, у которых нет доступа к эффективным предсказаниям наводнений, или предсказания которых не дают достаточной временной форы на то, чтобы эффективно среагировать на них. Параллельно с нашей работой над моделью наводнений, мы проводим базовые исследования улучшенных гидрологических моделей, которые, как мы надеемся, позволят правительствам не только выдавать более точные с пространственной точки зрения прогнозы, но и давать больше времени на подготовку.
Гидрологические модели принимают такие входящие данные, как осадки, солнечное излучение, влажность почвы и т.п., и выдают прогноз водного потока (и прочее) на несколько дней в будущее. Эти модели традиционно реализуются через комбинацию концептуальных моделей, приближающих различные ключевые процессы типа таяния снега, поверхностного стока, эвапотранспирации и прочего.
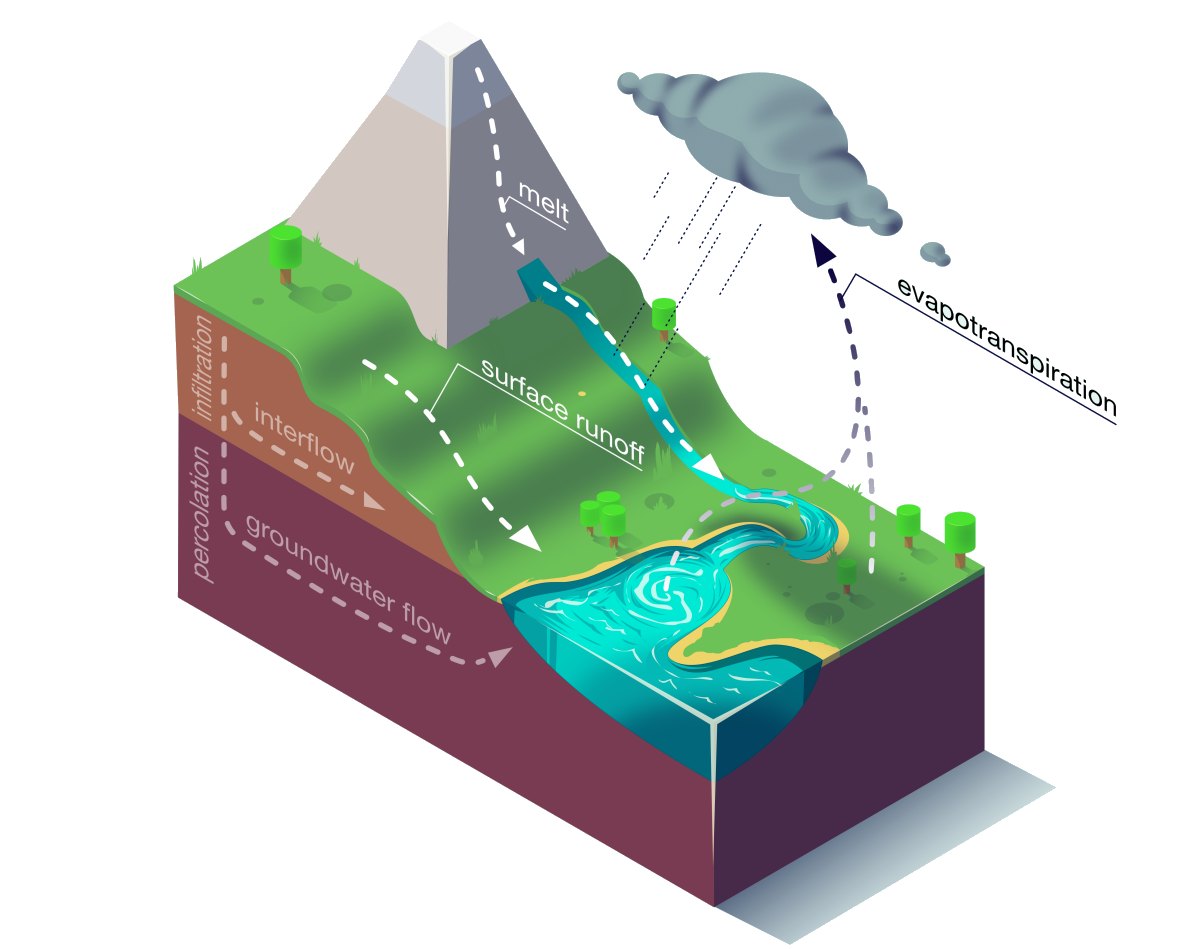 Ключевые процессы гидрологической модели
Ключевые процессы гидрологической модели
Также таким моделям обычно требуется тщательная ручная подстройка, а на территориях с недостатком данных они работают плохо. Мы изучаем вопрос того, как для решения обеих этих задач может подойти многозадачное обучение, и сделать гидрологические модели как более масштабируемыми, так и более точными. В совместном исследовании с группой из института машинного обучения при Линцском университете, под руководством Сеппа Хохрейтера разрабатывающей гидрологические модели на основе машинного обучения, Кратцерт с коллегами показали, что нейросети с долгой краткосрочной памятью показали себя в работе лучше любых классических гидрологических моделей.
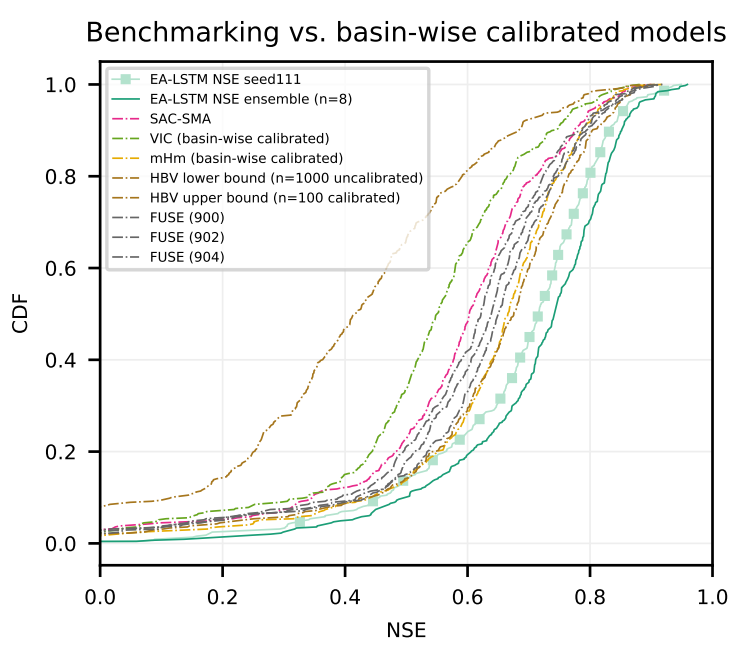 Распределение коэффициента эффективности модели Нэша-Сатклиффа различных бассейнов США в разных моделях. Модель EA-LSTM стабильно опережает широкий спектр часто используемых моделей.
Распределение коэффициента эффективности модели Нэша-Сатклиффа различных бассейнов США в разных моделях. Модель EA-LSTM стабильно опережает широкий спектр часто используемых моделей.
Хотя эта работа пока находится в стадии первоначальных исследований, мы считаем, что это важный первый шаг, и надеемся, что он уже может оказаться полезным для других исследователей и гидрологов. Мы считаем невероятной честью работать в крупной экосистеме исследователей, правительств и негосударственных учреждений над уменьшением последствий наводнений. Мы с восторгом оцениваем потенциальные последствия таких исследований, и надеемся увидеть, куда они нас заведут.
Автор: Вячеслав Голованов
Источник: https://habr.com/
Понравилась статья? Тогда поддержите нас, поделитесь с друзьями и заглядывайте по рекламным ссылкам!
