
 В последнее время слышно много жалоб: технический прогресс затормозился, научных открытий стало меньше, софт тормозит сильнее прежнего. Чуть ли не тотальная деградация. Однако нельзя отрицать экспоненциального роста вычислительной мощности компьютеров в последние десятилетия. Более того, закон Мура и революция IT — один из главных факторов экономического прогресса в XX–XXI вв. Давайте вспомним некоторые отрасли, которые кардинально продвинулись вперёд благодаря экспоненциальному росту вычислений. Один из очевидных примеров — моделирование (прогноз) погоды. Если вы не заметили, в последние десятилетия прогнозы погоды стали намного более детализированными, включая температуру с точностью до градуса, вероятность осадков, атмосферное давление, влажность, силу и направление ветра — всё это с почасовой раскладкой на день или несколько дней вперёд благодаря компьютерным вычислениям. В прежние времена такого невозможно было себе представить.
В последнее время слышно много жалоб: технический прогресс затормозился, научных открытий стало меньше, софт тормозит сильнее прежнего. Чуть ли не тотальная деградация. Однако нельзя отрицать экспоненциального роста вычислительной мощности компьютеров в последние десятилетия. Более того, закон Мура и революция IT — один из главных факторов экономического прогресса в XX–XXI вв. Давайте вспомним некоторые отрасли, которые кардинально продвинулись вперёд благодаря экспоненциальному росту вычислений. Один из очевидных примеров — моделирование (прогноз) погоды. Если вы не заметили, в последние десятилетия прогнозы погоды стали намного более детализированными, включая температуру с точностью до градуса, вероятность осадков, атмосферное давление, влажность, силу и направление ветра — всё это с почасовой раскладкой на день или несколько дней вперёд благодаря компьютерным вычислениям. В прежние времена такого невозможно было себе представить.
Прогноз погоды
До середины XIX века прогнозирование осуществлялось на основе исторических записей, примет, личных наблюдений и примитивных измерений (например, влажности). После изобретения телеграфа наблюдатели в разных местах начали обмениваться информацией для создания первых карт погоды. Сегодня эту задачу выполняет огромная сеть датчиков, включая тысячи метеостанций на земле и в верхних слоях атмосферы, тысячи судов и дрейфующих буёв, сотни метеорологических радаров, тысячи самолётов (на коммерческие лайнеры ставят специальную аппаратуру), а также сотни спутников. Вся информация передаётся на суперкомпьютер, где идёт обсчёт метеорологических моделей для численного прогнозирования Numerical Weather Prediction (NWP).
, пять дней (красный), семь дней (зелёный) и десять дней (жёлтый). Нижняя линия каждого графика отражает точность прогнозов для южного полушария, а верхняя — для северного. По мере развития спутниковых технологий точность прогнозов для южного полушария сравнялась с точностью прогнозов для северного полушария. Источник: Европейский центр среднесрочных прогнозов погоды (ECMWF).")
Степень точности метеорологической модели для прогнозов на высоте 5 км над уровнем моря на три дня (синий), пять дней (красный), семь дней (зелёный) и десять дней (жёлтый). Нижняя линия каждого графика отражает точность прогнозов для южного полушария, а верхняя — для северного. По мере развития спутниковых технологий точность прогнозов для южного полушария сравнялась с точностью прогнозов для северного полушария. Источник: Европейский центр среднесрочных прогнозов погоды (ECMWF).

С начала активного использования NWP в 80-е годы их точность значительно выросла. Кроме того, прогнозы стали более детализированными. Вычислительная сложность численного прогнозирования в значительной степени определяется разрешением модели. Например, текущая модель Global Forecast System (GFS), используемая Национальной метеорологической службой США (National Weather Service), делит атмосферу на участки 13×13 км. Мировым лидером в области моделей прогнозирования погоды является Европейский центр прогнозов погоды на средние расстояния (ECMWF), который увеличил разрешение своей модели с 210 км в 1979 году до 9 км в 2016 году.
Каждое удвоение разрешения увеличивает объём вычислений в 8 раз. В дальней перспективе сообщество прогнозирования погоды ставит целью получение моделей с разрешением 1 км с 200 вертикальными уровнями и учётом 100 переменных, что позволит точно моделировать изменение погоды на горных хребтах и других особенностях ландшафта, но потребует в 2000 раз больше вычислительной мощности.
В погодных моделях используется множество разных методов, например дифференциальные уравнения физических взаимодействий для моделирования температуры, ветра, давления и других переменных гидро- и термодинамики. Модели берут начальное состояние модели и предсказывают, что произойдёт через 24, 48, 72 или более часов.
Поскольку небольшие изменения в начальных условиях могут привести к большим различиям в результатах, в прогнозировании погоды часто используются методы ансамблей, при которых модель запускается много раз со слегка изменёнными начальными условиями, чтобы изучить различия в результатах. Это легко увеличивает объём вычислений в 50–100 раз.
 Ансамблевый прогноз возможных маршрутов циклона Уинстон и циклона Татьяна на запад. Несколько вариантов из ансамбля предсказывают движение в сторону Новой Зеландии. Изображение: Лаборатория исследования системы Земли в NOAA.
Ансамблевый прогноз возможных маршрутов циклона Уинстон и циклона Татьяна на запад. Несколько вариантов из ансамбля предсказывают движение в сторону Новой Зеландии. Изображение: Лаборатория исследования системы Земли в NOAA.
Чтобы оценить прогресс в точности прогноза температуры, группа исследователей из Массачусетского технологического института сравнила статистику NOAA о производительности их суперкомпьютеров с 1950-х годов и точность прогнозов, которая измерялась как средняя разница (в градусах Фаренгейта) между прогнозом и фактической температурой.
Рост производительности компьютерных систем:
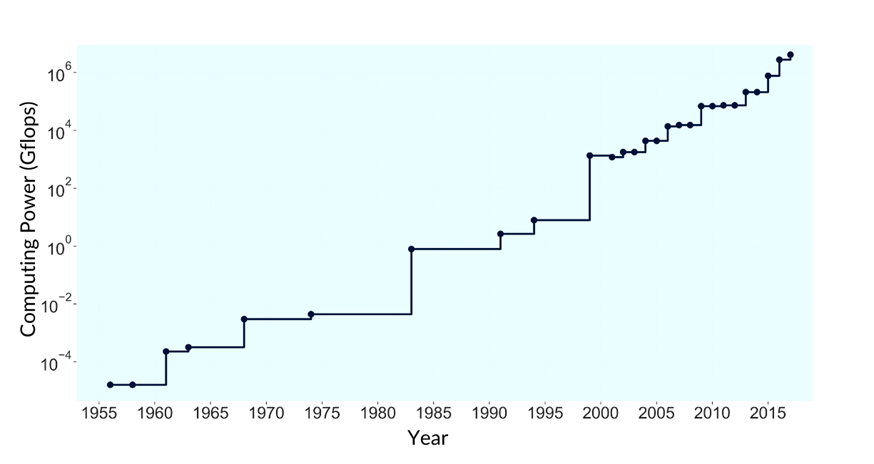
Средняя ошибка прогнозирования:
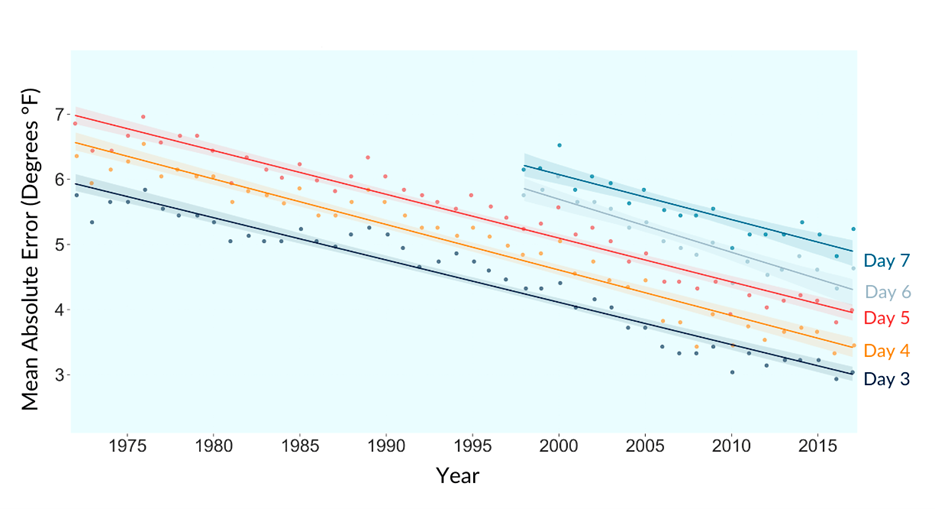
Оказалось, что увеличение вычислительной мощности довольно точно коррелирует с повышением точности прогнозов:
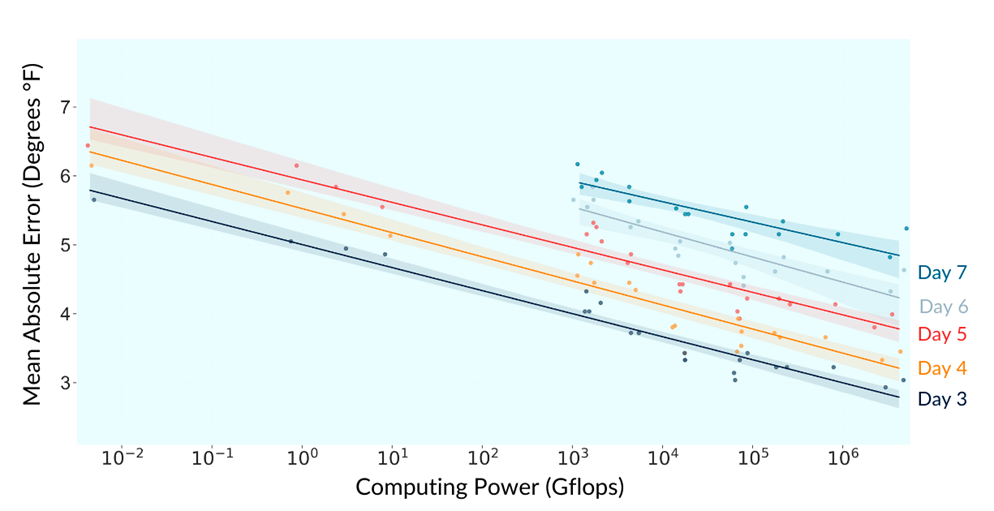
Например, погрешность прогнозов на три дня снизилась с 5,8 °F в 1972 году до 3,0 °F в 2017 году, то есть на 47%.
Вычислительная мощность, используемая NOAA для прогнозирования погоды, увеличилась с 1956 по 2017 годы почти в триллион раз, в среднем на 48,2% в год, что примерно соответствует закону Мура.
Таким образом, увеличение вычислительной мощности в 10 раз приводит к снижению ошибки прогнозирования примерно на 0,33 °F. Анализ исходных данных показал, что улучшение точности прогнозов практически всегда можно объяснить увеличением мощности суперкомпьютеров или оптимизациями алгоритмов.
Фолдинг белков
Аналогичный прогресс наблюдается в ещё одной научной дисциплине — расчёте фолдинга белков для моделирования свойств новых протеинов, в том числе при поиске лекарств.
Как известно, белки — это молекулярные машины, которые выполняют практически все важные биохимические процессы в живом организме. Процесс производства нового протеина в организме включает два этапа:
- сбор цепочки из базовых единиц;
- фолдинг в 3D-структуру с характерными свойствами.
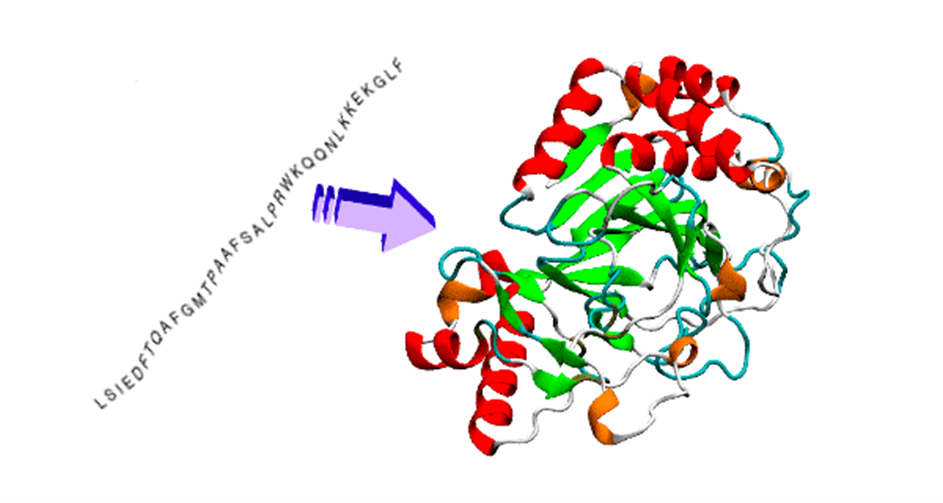
Схема свёртывания (фолдинга) имеет ключевое значение, потому что определяет структуру белка, его стабильность и другие свойства, важные для медицины. Это невероятно сложная задача для вычисления. Теоретически у белка умеренного размера может быть 10300 возможных конфигураций.
Оценка компьютерных систем для расчёта фолдинга белков происходит раз в два года на мероприятиях Critical Assessment of protein Structure Prediction (CASP). Участникам предлагают сотни цепочек протеинов, а системы должны рассчитать итоговую структуру. Успех измеряется с помощью оценки GDT_TS (Global Distance Test_Total Score). Она рассчитывает сходство между результатами предсказания структуры белка и реальной структурой белка, которую изучили средствами ЯМР-спектроскопии или рентгеновской кристаллографии. Максимальная оценка ― 100, когда предсказанная структура полностью совпадает с реальной.
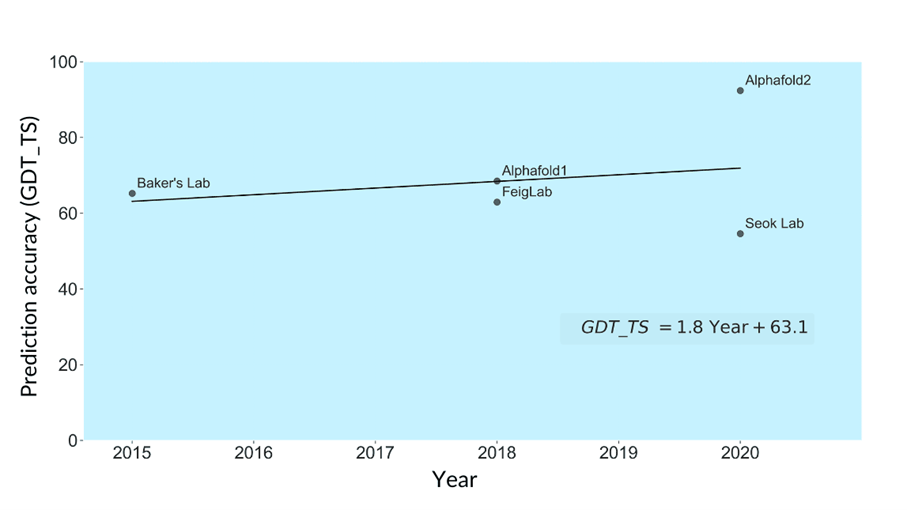
К сожалению, в открытых источниках удалось найти вычислительную мощность только пяти моделей-участников CASP. Вот точность компьютерного моделирования свойств протеинов (GDT_TS) с соревнований Critical Assessment of Protein Structure Prediction Experiments (CASP):
Вычислительная мощность систем, которые обсчитывают фолдинг белков:

Корреляция между точностью прогнозирования и вычислительной мощностью лабораторий:
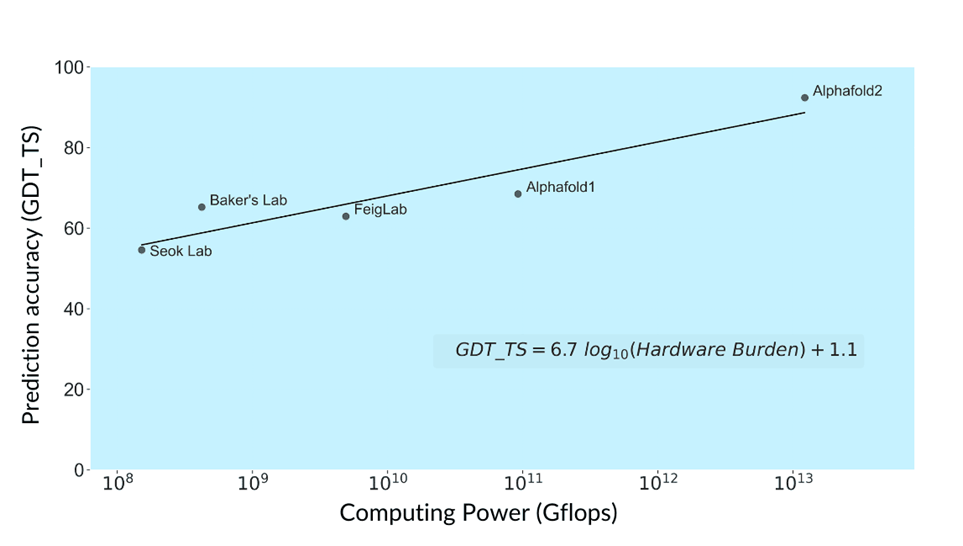
В целом здесь наблюдается быстрый прогресс. За шесть лет с 2015 по 2021 годы оценка GDT_TS выросла с 65 до 92%. Процесс сопровождался огромным ростом используемой вычислительной мощности — с 421 млн гигафлопс до 12,2 трлн гигафлопс, т. е. в среднем четырёхкратный рост в год.
Бурение нефтяных скважин
Наконец, ещё одна область, в которой заметный прогресс коррелирует с увеличением мощности компьютерных систем — это разведка нефтяных месторождений, в частности бурение разведывательных скважин.
Одна скважина на суше стоит от $4,9 млн до $8,3 млн, а на шельфе — до $650 млн, так что «сухие скважины» дорого обходятся.
По этой причине в 1950-е годы возникла новая отрасль науки ― сейсмическое моделирование. Оно моделирует физическую структуру Земли путём изучения, как сейсмические волны распространяются и отражаются от различных материалов. С вычислительной точки зрения это предполагает решение серии волновых уравнений с физическими параметрами геологических материалов.
Но вплоть до конца 1970-х вычислительные мощности были недостаточны для решения полного набора волновых уравнений в сложных моделях. Только в 1982 году производительность суперкомпьютеров впервые позволила рассчитать настоящую 3D-модель. Впоследствии она была расширена до 4D (с учётом времени распространения сейсмических волн).
По данным Управления энергетической информации США, показатель успешности бурения вырос с 10% в 1940-е до 70% в 2010-е.
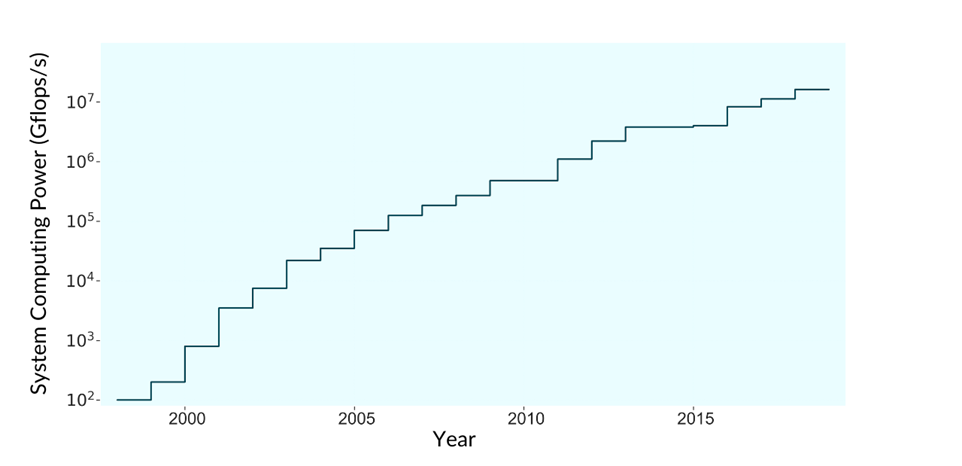
Сегодня у всех крупных нефтяных корпораций есть собственные суперкомпьютеры, причём очень мощные. Например, в суперкомпьютере Eni установлено 3200 графических процессоров Nvidia Tesla, что обеспечивает производительность 18,6 петафлопс. Все нефтяные корпорации значительно наращивали мощность своих систем в последние 30 лет.
По данным энергетического портала iHS Markit можно проследить, как улучшалась эффективность одной из крупнейших нефтяных компаний BP в бурении разведочных морских скважин (именно здесь сейсмическое моделирование является основным методом исследования).
Рост вычислительных мощностей BP:
Успешность бурения скважин в корреляции с ростом вычислительных мощностей (сглажен по времени):
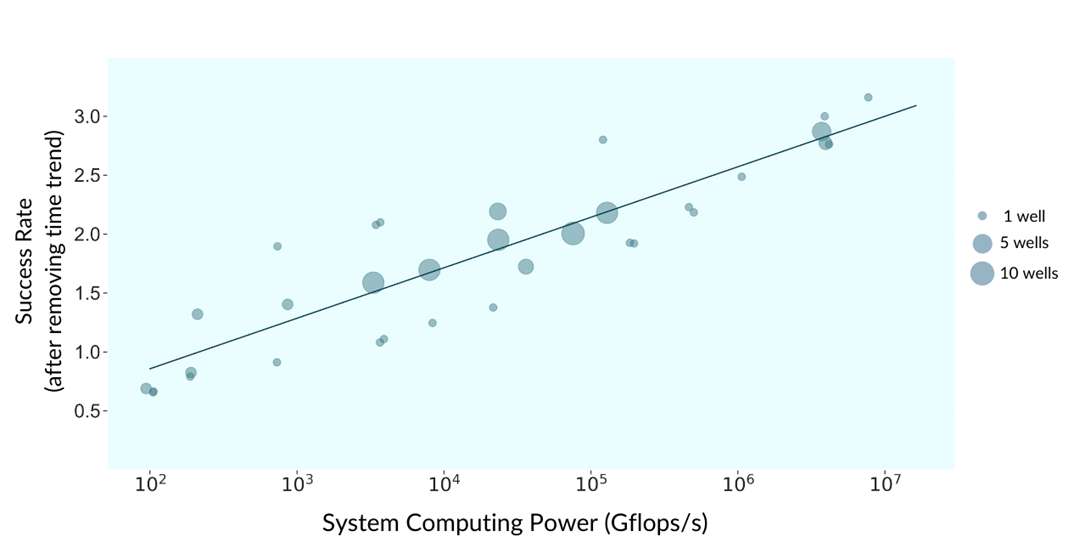
Важно отметить: это улучшение показателей происходит на фоне того, что бурить становится всё труднее, поскольку более лёгкие участки уже освоены, то есть со временем коэффициент успешности бурения при данном объёме вычислительной мощности должен падать.
В итоге группа исследователей из Массачусетского технологического института под руководством Нила Томпсона пришла к выводу, что экспоненциальный рост компьютерных вычислений обеспечил линейный прогресс в ряде важных отраслей мировой промышленности. Научная статья с выводами опубликована 28 июня 2022 года на сайте препринтов arXiv.org (doi: 10.48550/arXiv.2206.14007).
Будущее вычислений
Из-за большого влияния неопределённости люди очень плохо справляются с предсказанием далёкого будущего. Грубо говоря, малейшее случайное событие сильно изменяет ход истории — и будущее кардинально меняется, как маршрут циклона Уинстон, упомянутый выше.
С другой стороны, научно-технический прогресс в любом случае идёт по определённой траектории. Следующие открытия логически вытекают из предыдущих — и они, по сути, неизбежны после того, как сложились все предпосылки и человечество вышло на определённый уровень. Вопрос только во времени и темпах поступательного развития.
Поэтому можно с большой долей вероятности предполагать, что некоторые события обязательно произойдут, если сложатся условия.
Первый путь. Если человечество благодаря квантовым компьютерам или другим прорывным технологиям продолжит экспоненциальный рост компьютерных вычислений, вероятно, довольно скоро нас ждёт технологическая сингулярность.
Второй путь. Если закон Мура и закон масштабирования Деннарда прекратят своё действие, то экспоненциальный рост вычислений в прежнем виде прекратится, примет иную форму или будет проявляться иначе, возможно, только в отдельных сферах. В этом случае появление сильного ИИ и технологической сингулярности откладывается на неопределённый срок.
Трансформация закона Мура в новую форму порождает много специализированного железа, что видно на примере нишевых, высокопроизводительных архитектур нового поколения, таких как Tesla Dojo и Adapteva Epiphany-V.
 Adapteva Epiphany-V
Adapteva Epiphany-V
По мнению некоторых аналитиков, универсальные архитектуры прошлого ― x86, ARM и RISC-V ― в конце концов будут заброшены. Это коснётся и базовой модели вычислений как потока последовательных инструкций между центральным процессором и памятью. На смену придёт более простое и эффективное оборудование, компиляторы микросхем, новые операционные системы, кастомные CPU и ASIC с производством по требованию из загружаемых шаблонов в партиях от 10 шт. Если такой прогноз сбудется, то нас ждёт интересное будущее.
Вывод
Итак, за последние десятилетия компьютерная индустрия обеспечила науке и промышленности экспоненциальный рост скорости вычислений. Вопрос в том, как его использовать. Например, в программировании это позволило создать несколько дополнительных уровней абстракции и упростить процесс разработки. Пришлось отказаться от низкоуровневого программирования и пожертвовать производительностью, но зато мы наблюдаем эффект коммодификации вычислений и проникновение софта в новые сферы экономики и человеческих отношений — то, что называется software is eating the world.
Хотя закон Мура может прекратить своё действие для универсальных CPU, но вычислительная революция продолжается. В некоторых областях прогресс даже ускоряется в последние годы. Например, оптимизация алгоритмов для смешанного целочисленного программирования в 2001–2020 годы составила 50 раз, в то время как аппаратная часть за эти годы ускорилась в 20 раз. Таким образом, общее ускорение обсчёта задач MILP за два десятилетия зафиксировано на два порядка (в 1000 раз).
Вообще, проблема P vs NP остаётся самой важной из нерешённых математических проблем человечества — она несёт на удивление много практической пользы для реальной экономики. Так что у нас ещё очень большое пространство для революционных открытий.
Автор: Анна Колосова
Источник: https://habr.com/