
 Для современного цифрового предприятия данные – это фундамент для выработки эффективных управленческих решений, как оперативных, так и стратегических. Однако на пути к принятию решений «сырые» исходные данные превращаются в корпоративные знания. Сегодня мы видим несколько направлений такой трансформации, как на уровне аккумулирования цифрового опыта компании, так и на уровне самих данных. Аналитики Gartner выделяют отдельную группу ИТ-решений – платформы цифрового опыта (Digital Experience Platforms, DXP), для которых ежегодно выпускается «Магический квадрант». В своем анализе DXP-платформ аналитики Gartner, в первую очередь, фокусируют внимание на интеграции клиентских данных из различных источников. Так, в числе лидеров рыночного сегмента – компания Adobe, у которой, по мнению Gartner, – зрелое решение DXP, включающее управление контентом, аналитику и функции персонализации.
Для современного цифрового предприятия данные – это фундамент для выработки эффективных управленческих решений, как оперативных, так и стратегических. Однако на пути к принятию решений «сырые» исходные данные превращаются в корпоративные знания. Сегодня мы видим несколько направлений такой трансформации, как на уровне аккумулирования цифрового опыта компании, так и на уровне самих данных. Аналитики Gartner выделяют отдельную группу ИТ-решений – платформы цифрового опыта (Digital Experience Platforms, DXP), для которых ежегодно выпускается «Магический квадрант». В своем анализе DXP-платформ аналитики Gartner, в первую очередь, фокусируют внимание на интеграции клиентских данных из различных источников. Так, в числе лидеров рыночного сегмента – компания Adobe, у которой, по мнению Gartner, – зрелое решение DXP, включающее управление контентом, аналитику и функции персонализации.
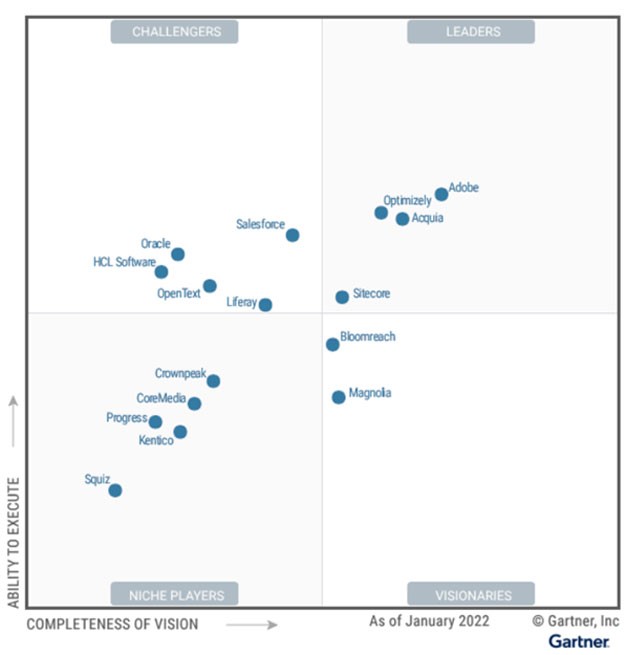
Компания Salesforce вошла в число лидеров, поскольку сделала частью своей экосистемы систему управления контентом, CRM, а также функционал автоматизации маркетинга. Аналитики Gartner считают, что платформа Salesforce DXP вместе с CRM и CDP (Customer Data Platform) обеспечивает наиболее полную экосистему услуг цифрового опыта.
Еще один интересный участник Магического квадранта Gartner DXP – компания Liferay. Ее разработка – Liferay DXP – отличается высокой способностью к интеграции (обширный набор API и разъемов, готовые функции для поддержки сценариев использования B2B и B2E), а также наличием open source версии. Она дает возможность дополнять исходный код своими разработками и создавать закрытые коммерческие продукты. Например, по этому пути двигается российская компания L2U – она разработала на базе СПО Liferay базу корпоративных знаний InKnowledge и омниканальную платформу L2U.

Корпоративные СУЗ
Термин «системы управление знаниями» (СУЗ) начал использоваться еще в середине 1990-х годов в связи с задачами, возникшими при обработке больших объемов информации в крупных корпорациях. Он связан с поддержкой процессов создания, распространения, обработки и использования знаний внутри предприятия.
В 2020 г. объем мирового рынка ПО для управления знаниями, по данным Verified Market Research, составил 22,45 млрд. долл. и к 2028 г. 58,81 млрд. долл. с ежегодным ростом на уровне 12,5% в период 2021 – 2028 гг.
Задача СУЗ — накапливать не разрозненные данные, а структурированные и формализованные знания, то есть правила, закономерности и принципы, позволяющие решать реальные производственные задачи. Это дает возможность сделать глубокие корпоративные знания доступными для сотрудников и повторно их использовать на уровне всей большой корпорации. При этом знания классифицируются и распределяются по категориям в соответствии с конкретной архитектурой и системными подходами к управлению знаниями.
Система управления знаниями InKnowledge.
По оценке разработчиков, InKnowledge – это система, которая структурирует знания и направлена на улучшение пользовательского опыта. Она заточена под хранение и организацию контента: статьи, новости, документы, скрипты, переиспользуемые фрагменты (например, реквизиты компаний) и другие виды контента, структуру которых пользователь создает самостоятельно. Все загружаемые файлы хранятся во внутренней медиа-библиотеке InKnowledge и имеют уникальный идентификатор, что позволяет, например, при необходимости в один клик заменить изображение или документ во всех местах, где он используется.
Размещаемые знания в системе распределяются по различным тематическим областям, которые либо пересекаются, либо строго изолированы. Кроме этого, система предназначена для интеграции с другими системами, ботами, виртуальными помощниками, чтобы выступать для них единым поставщиком информации.
Структура Базы знаний InKnowledge имеет форму дерева страниц, причем, каждая страница собирается из виджетов и может выглядеть по-разному в зависимости от того, к каким категориям контента принадлежит. В этой системе реализованы также гибкие поисковые возможности, включая полнотекстовый, морфологический поиск (по корням слов), математический поиск (с использованием специальных символов), автопродление поискового запроса и поиск с игнорированием опечаток.
База знаний помогает компаниям сократить время на поиск актуальной и достоверной информации и предоставить доступ к ней для клиентов, партнеров, собственных филиалов и представительств. Кроме этого, с помощью Базы Знаний можно настроить портал самообслуживания для клиентов и закрыть линии техподдержки без участия операторов и менеджеров,- рассказывают в компании.
База знаний CraftTalk KMS.
Корни этой платформы, которая вышла на рынок в феврале нынешнего года, уходят в известную разработку AI-платформы CraftTalk для текстовых контакт-центров (чат-центр с искусственным интеллектом).
В платформе CraftTalk блок базы знаний всегда был одним из ключевых для организации совместной работы операторов Call-центров и искусственного интеллекта. Именно он помогает оперативному качественному обучению бота и эффективным ответам,- рассказывает Михаил Сбитинков, технический директор и сооснователь компании CraftTalk.
Решение CraftTalk KMS представляет собой базу данных, которая хранит, распределяет и управляет всей собранной корпоративной информацией. Предприятия могут использовать его как верифицированный омниканальный источник знаний по всем необходимым вопросам: внутренние процедуры компании, HR-информация, база знаний для IT, бизнес-процессы, информация о проектах, быстрый доступ к информации через чат, рассылки новостей, необходимый рабочий инструмент для корпоративного Call-центра и текстового помощника на базе искусственного интеллекта. Простой и удобный интерфейс системы реализован по принципу wiki.
Система для управления знаниями (Knowledge Management System) CraftTalk KMS построена в парадигме No-Code для максимально быстрого внедрения и эффективного обучения сотрудников работе с ним: интуитивно понятный графический редактор сценариев (скриптов) для операторов или ботов, наглядные блок-схемы.
Данные и информация консолидируются и структурируются, что позволяет каждому члену команды оперативно находить необходимую информацию, быстро погружать в нужную тематику новых сотрудников, а также легко обмениваться информацией с сотрудниками внутри компании и за ее пределами, если это одобрено политикой информационной безопасности,- рассказывают в компании.
Облачная технология CraftTalk позволяет пользоваться корпоративной базой знаний прямо в чате мессенджера – нет необходимости переключаться в другие системы, интеграция базы знаний выводит варианты ответа прямо в чат.
Решение легко интегрируется с уже существующими базами знаний компаний и другими корпоративными системами. По мнению Дениса Петухова, генерального директора CraftTalk, СУЗ CraftTalk KMS – решение для полноценного импортозамещения таких популярных зарубежных продуктов, как КMS Lighthouse, Confluence (Atlassian), Notion.
СУЗ Minerva Knowledge/Naumen KMS.
Minerva Knowledge – это решение компании MinervaSoft по управлению знаниями для среднего и крупного бизнеса с большим количеством линейного персонала. Система выступает единым источником информации для всей компании: управление персоналом, клиентский сервис, коммерческие службы, маркетинг и PR, юридические службы, делопроизводство и бизнес-процессы, офисные сотрудники, подразделения эксплуатации, помогает синхронизировать контент во внешних и внутренних источниках, обеспечивает информирование об изменениях и быстрый доступ к информации за счет точного поиска.
Виджет Minerva встраивается в корпоративные ИТ-системы, чтобы понимать, что сотрудники делают и рекомендовать подходящие знания.
Весной 2021 г. компания NAUMEN приобрела долю в компании MinervaSoft, и дальнейшее развитие продукта идет под брендом Naumen KMS. Решение Naumen KMS позволит крупным и средним компаниям создавать базы знаний для операторов контакт-центра и сотрудников фронт-офиса. Например, при интеграции с чат-ботом и сайтом компании система позволит избежать ситуации, когда клиенты получают разные ответы в разных каналах обслуживания.
Продукт помогает создать универсальный источник информации для всех сотрудников, в котором синхронизируются и своевременно обновляются сведения о продуктах, услугах и бизнес-процессах компании.
В компании Naumen говорят, что в конкретных внедрениях удается снизить длительность обработки обращений на 10% уже через три месяца после запуска системы.
База знаний «Битрикс24».
С помощью этого продукта в рамках «Битрикс24» создается единое хранилище корпоративных данных, которое легко пополняется и легко редактируется всеми сотрудниками компании. По сути, это мультимедийное пространство корпоративных знаний, созданное для систематизированного хранения регламентов, статей, чек-листов, документации и других данных в компании. Нужная информация отыскивается в нем за считанные секунды – для этого в системе работает умный поиск.
При этом можно создавать отдельную базу знаний для каждого проекта внутри рабочей группы – с правилами, алгоритмами и другой важной информацией: все участники проекта по умолчанию получат к ней доступ, смогут коллективно создавать, обсуждать и редактировать статьи.
Создать и редактировать Базу знаний сможет любой сотрудник. Для этого используются шаблоны, готовые блоки, в которых на лету можно менять тексты, изображения и видеоролики.
СУЗ «Ростелеком».
Система управления знаниями — это цифровой продукт «Ростелеком Контакт-центр», предназначенный для использования в контактных центрах и службах поддержки клиентов. С его помощью создается единое информационное пространство для службы поддержки клиентов телеком-компании. В этом информационном пространстве размещаются все информационные материалы, которые используются при обслуживании клиентов.
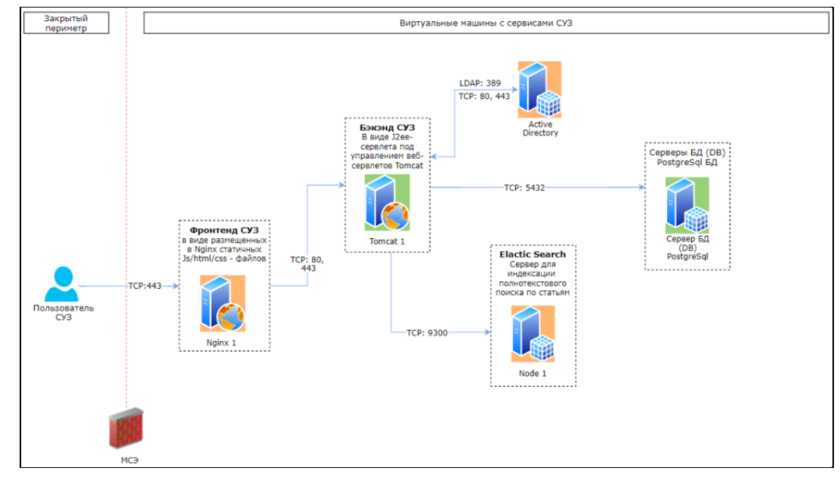
Источник: Описание Системы управления знаниями, АО МЦ НТТ
Выявление неявных связей в данных
Важная часть решений интеллектуальной обработки данных – выявление новых знаний: некоторых паттернов, неявных связей, недостающих данных и т.п.
Выявление паттернов – это, можно сказать, стандартная задача технологий машинного обучения. И, в общем, успешность ее решения зависит от количества и качества существующих данных, компетенции специалистов и имеющихся ресурсов. Но, в частности, со стандартными задачами на коммерческом рынке она справляется успешно,- отмечает Александр Хледенев, директор по цифровым решениям компании «ВС Лаб».
Если под недостающими данными имеется в виду идентификация отклонений в ряду «нормальных» данных, продолжает эксперт, то это задача технологий продвинутого обнаружения аномалий, и она означает обнаружение объектов (их групп), событий или паттернов, отличных от ожидаемых.
При таком подходе модели обучаются на «нормальных» данных или событиях и автоматически или на основе моделей с «ненормальным» предыдущим поведением позволяют оперативно или упреждающе обнаружить отклонение,- поясняет Александр Хледенев.
Такие подходы используются в задачах кибербезопасности, для борьбы с мошенничеством, мониторинга работоспособности ИТ-систем и др. С распространением Интернета вещей технологии такого рода получают применение в задачах мониторинга физических активов и предиктивного обслуживания оборудования.
Природа задач мониторинга обусловливает необходимость обнаружения аномалий в режиме, близкому к реальному времени,- говорит Александр Хледенев.- Поэтому они реализуются с использованием платформ потокового анализа данных и in-memory computing, что делает реализацию дорогой.
Правда, с распространением Edge Computing (оборудования для граничных, периферийных вычислений) и систем децентрализованного (федеративного) ИИ, стоит рассчитывать на ее удешевление и расширение применения, полагает эксперт.
Для задачи выявления неявных связей сегодня активно используется математический аппарат графов знаний (knowledge graphs).
Алгоритмы и анализ графов лучше всего подходят для обнаружения направлений и непрямых, неочевидных взаимосвязей между различными сущностями и объектами исследования,- рассказывает Александр Хледенев.- В силу этого анализ графов получил распространение на рынке кибербезопасности и как инструмент для специальных служб и силовых структур (например, известная американская система Palantir,), а также используется для анализа социальных сетей.
Нередко такие продукты на рынке объединяют под термином OSINT (Open Source Intelligence) а для исследований (расследований) применяется одноименный фреймворк. Инструментарий OSINT позволяет быстро и наглядно представить все инциденты, а это, в свою очередь, дает возможность сотрудникам в связке с ИИ быстро и качественно их обработать, например, быстро купировать инциденты, связанные с мошенничеством и отмыванием денег.
Коммерциализация таких решений пока находится на ранней стадии, считает Александр Хледенев. Однако они получают все большую популярность в различных областях деятельности, помимо кибербезопасности. Например, они используются для построения деревьев знаний с целью конкурентной разведки, анализа поставщиков, обнаружения технологических трендов для раннего инвестирования. Есть и более «приземленные» сценарии – анализ пользовательской корзины для ритейла или оптимизация маршрутов для транспортных компаний. К числу популярных областей применения относится также анализ заемщика для оценки кредитного лимита и подготовки кросс-предложений со стороны банка.
Как рассказывает Алиса Селиванова, лидер юнита «Решения и технологии кредитного антифрода» в Сбербанке, компания выбрала для создания «портрета» клиента механизм больших графовых моделей. По оценке Алисы Селивановой, такая скоринговая модель используется в течение нескольких лет, и за это время она не деградировала.
Графовая аналитика
Аналитики Gartner в 2020 г. выделили в числе главных тенденций в обработке данных и аналитике технологии графовой аналитики — набора методов, ориентированных на анализ структуры связей между объектами.
Ценность данных будут формировать взаимосвязи,- уверены в Gartner.- К 2023 г. они будут способствовать быстрой констектуализации для принятия решений в 30% компаний по всему миру, где будут использоваться для исследования отношений между организациями, людьми и транзакциями.
О том, что технологии Graph Analytics сегодня весьма актуальны, говорят различные рыночные исследования. Так, аналитики Markets and Markets в своем глобальном прогнозе до 2024 г. предсказывают ежегодный рост этого сегмента рынка на 34,0%: с 584 млн. долл. в 2019 г. до 2522 млн. долл. к 2024 г. Как подчеркивают аналитики, основными драйверами роста рынка являются: растущий спрос на анализ запросов с низкой задержкой и способность выявлять взаимосвязи между данными в режиме реального времени.
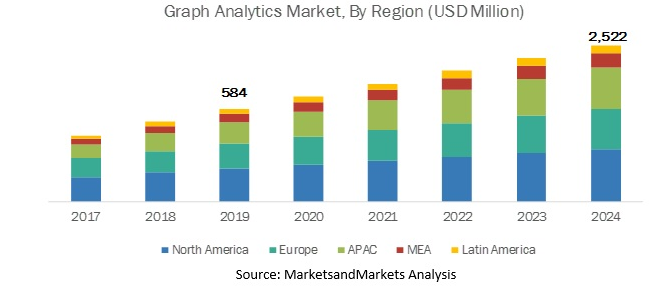
По данным отчета Graph Analytics Market Size, Share, Potential Growth, Competitive Analysis 2022-2027, подготовленного аналитиками Market Research Future, объем рынка Graph Analytics будет расти с CAGR на уровне 31,6% и достигнет к концу прогнозируемого периода размера 2885,2 млн. долл.
Рынок Graph Analytics сегментирован по аналитическим приложениям. Ожидается, что сегмент оптимизации маршрутов станет самым быстрорастущим сегментом на этом рынке из-за растущей потребности в определении наилучшего маршрута в логистике, транспортных услугах, розничной торговле и электронной коммерции. Среди других растущих сегментов применения Graph Analytics – аналитика клиентов, управление рисками и соответствием регуляторным требованиям, рекомендательные механизмы, обнаружение мошенничества, управление операциями и управление активами.
Речь идет о том, что с помощью средств графовой аналитики данных будут обнаруживаться связи, которые нелегко было выявить с помощью традиционных аналитических инструментов. Например, в условиях, когда мир стремится быстро и правильно реагировать на меняющиеся условия пандемии, графовые технологии помогут связать пространственные данные на смартфонах жителей и выявить людей, находившихся в контакте с лицами, чьи тесты на коронавирус дали положительный результат.
В сочетании с алгоритмами машинного обучения эти технологии могут использоваться для анализа тысяч источников данных и документов с тем, чтобы помочь врачам и специалистам в области организации здравоохранения быстро найти новые возможные методы лечения или факторы, которые способствуют негативным проявлениям у некоторых пациентов.
Например, в Сбербанке ИИ в 100% случаев принимает решения о выдаче кредитов физическим лицам, изучая цифровые следы заемщика. По оценке Германа Грефа, объем информации, содержащийся в них, позволяет говорить о том, что в банке формируется цифровой двойник человека. И эти двойники ежедневно прибавляют в «весе» приблизительно на 500 МБ, поскольку постоянно действующие программы умного мониторинга каждый день приносят новые данные о клиентах и заемщиках.
Для того чтобы аналитические процессы скоринга происходили со скоростью, близкой к реальному времени, обычно создаются real-time витрины данных. Они строятся на базе специальных высокопроизводительных СУБД, ориентированных на очень быструю обработку данных, например, открытая СУБД Apache Cassandra. При этом для задач построения сложных связей между многими сущностями активно используется аппарат графовых нейронных сетей (Graph Neural Network, GNN).
По сути, графовые нейросети — это способ применения классических моделей нейронных сетей к данным в виде графов.
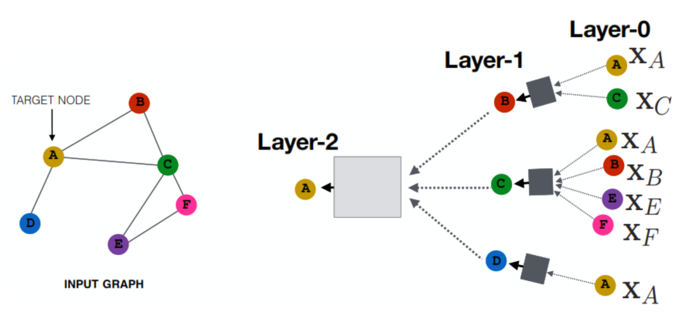
Источник: Блог компании Mail.ru Group на Habr, май, 2021 г.
Специфическая особенность GNN заключается в ом, что один ее слой – обычный полносвязный, с той лишь разницей, что веса в нем применяются не ко всем входным данным, а только к тем, которые являются соседями конкретной вершины в графе, в дополнение к ее собственному представлению с предыдущего слоя. Особенности представления данных в GNN обусловили ее популярность для создания рекомендательных систем, например, таким образом моделируют взаимодействие пользователей с товарами, чтобы с помощью ранжирования результатов выбирать персонализированные предложения по товарам и в реальном времени показывать конкретным пользователям.
Онтологии – механизм создания семантических моделей объектов, ситуаций, процессов
Термин «онтология» пришел из философии, где он подразумевает учение о всем сущем в общих философских категориях: бытие, субстанция, причина, действие, явление. В инженерии знаний под онтологией понимается детальное описание некоторой проблемной области, которое используется для ее формального описания. Можно сказать, что онтология — это спецификация некоторой области, которая включает в себя словарь терминов этой области и множество логических связей (типа «элемент-класс», «часть-целое»), которые описывают, каким образом эти термины соотносятся между собой. Важно, что в отличие от философского прообраза, компьютерные онтологии дают возможность представить понятия предметной области в таком виде, что они становятся пригодными для машинной обработки.
Интерес к использованию онтологий для создания корпоративных СУЗ возник достаточно давно.
Онтологический подход к проектированию СУЗ как раз и позволяет создавать системы, в которых знания, накопленные внутри организации, становятся доступными для большинства пользователей. Основные преимущества этого подхода: онтология представляет пользователю целостный, системный взгляд на определенную предметную область (ПрО); знания о ПрО представлены единообразно, что упрощает их восприятие; построение онтологии позволяет восстановить недостающие логические связи ПрО»,- писали Анатолий Гладун и Юлия Рогушина в своей статье «Онтологии в корпоративных системах» в журнале «Корпоративные системы» в 2006 г.
Авторы предложили тогда иллюстрацию знаний корпоративной СУЗ в виде корпоративной памяти, которая фиксирует информацию из различных источников и делает эту информацию доступной специалистам для решения производственных задач.
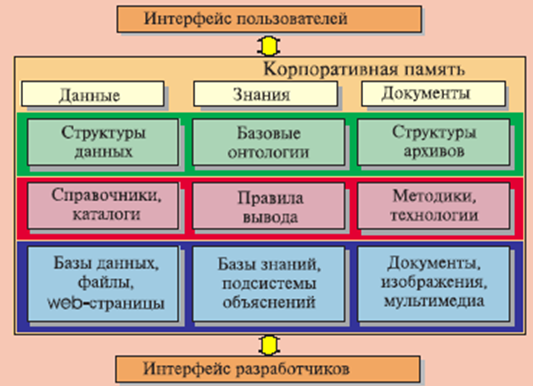
Источник: Онтологии в корпоративных системах. Часть I. А.Я. Гладун, Ю.В. Рогушина, журнал «Корпоративные системы» (№1, 2006)
В 2020 г. аналитики Gartner в исследовании новых технологий Hype Cycle for Emerging Technologies предсказали для онтологий выход на плато продуктивности в течение 2-5 лет.
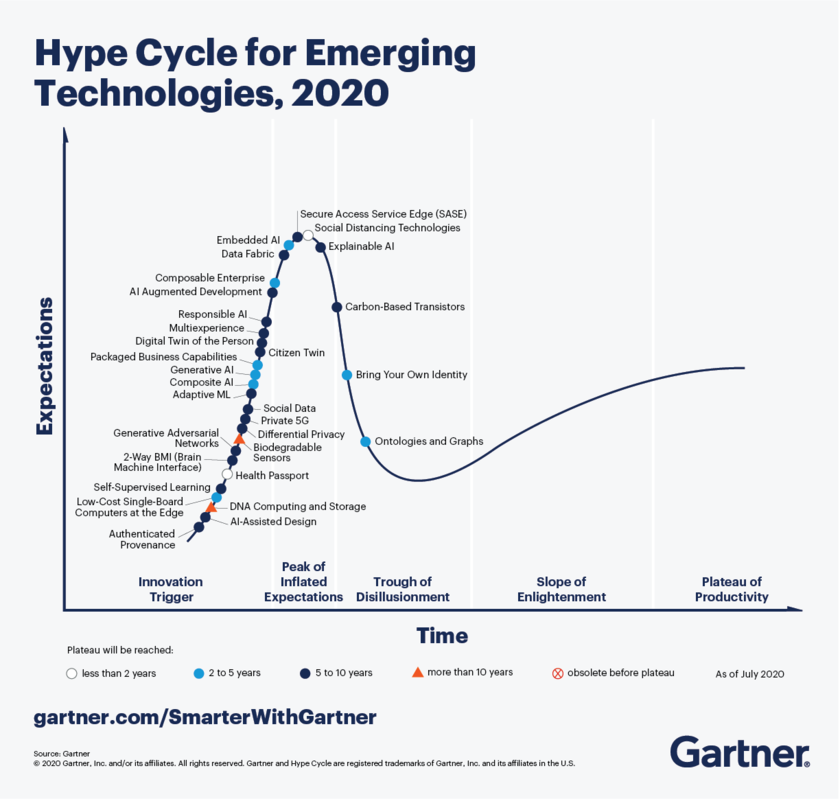
Яркий представитель семантической парадигмы – Semantic Web, базирующийся на онтологических ресурсах большого объема и специально разработанных для них языке онтологий Web Ontology Language (OWL). Язык OWL развивается консорциумом W3C и стал стандартом de facto не только для Semantic Web, но и других технологических направлений, например, информационного поиска в больших массивах неструктурированных данных и обработки текстов на естественном языке.
В числе критически важных аспектов Semantic Web стоит упомянуть два:
- Мульти-язычность контента. Semantic Web, по сути, предназначен для того, чтобы поддерживать эффективный доступ к информации независимо от того, на каком языке она представлена изначально. Надо сказать, что решение этой проблемы специалисты связывают в значительной мере с решением проблем онтологического инжиниринга и автоматической обработкой ЕЯ-текстов.
- Еще одна существенная проблема Semantic Web связана с обеспечением его стабильности. Это направление предполагает серьезные усилия в области стандартизации, что должно обеспечить создание надежных технологий для формирования пространств знаний.
Именно проблема стандартизации представляется сегодня одной из ключевых позиций в проблематике Semantic Web, поскольку от ее решения напрямую зависит возможность создания открытых и/или коооперативных семантических систем на базе ранее созданных онтологий.
В схеме, которую специалисты называют «слоеным пирогом» Тима Бернерс-Ли (по имени идеолога концепции Semantic Web), ее нижние уровни усилиями исследовательских коллективов и международного консорциума W3C (WWW Consortium) разработаны и реализованы рекомендации по форматам XML, Namespace (пространства имен) и RDF. Они в настоящее время существуют на уровне стандартов de facto. Можно констатировать, что результаты работ по данному направлению уже перешли из стадии исследований в стадию практического использования, в том числе, в коммерческих системах.
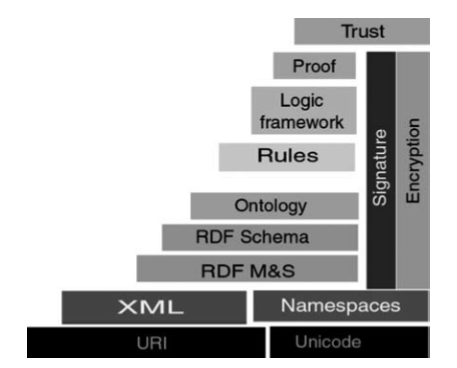
Так, на уровне RDF-схем предложены и поддерживаются W3C стандарты RDFS (RDF-схем), которые позволяют специфицировать словари используемых терминов, а также разрабатываются соответствующие спецификации для существующих и новых приложений.
А вот на онтологическом уровне (Ontology) «слоеного пирога» ситуация несколько иная. По сути, в этом направлении был создан достаточно мощный задел в рамках исследований по представлению знаний, в частности, общие подходы к представлению знаний типа фреймов, семантических сетей и т.п. Вместе с тем работа по стандартизации средств представления знаний онтологического уровня еще далека от завершения, а создание соответствующих средств онтологического инжиниринга в настоящее время представляет собой одну из «горячих точек» данной области.
Основными направлениями исследований и разработок здесь являются следующие:
- Создание более мощных средств спецификации онтологий, обеспечивающих логический вывод на знаниях и проверку целостности знаний.
- Создание средств поддержки целостности онтологических спецификаций в процессе эволюции, как спецификаций самих моделей, так и стандартов.
- Создание средств спецификации перекрестных ссылок между словарями и конвертирования спецификаций.
Почему это важно для корпоративных информационных систем? Фактически онтологии – это метаязык, который хорошо воплощается в виде ПО. Поэтому этот инструмент получил широкое распространение: от создания семантических «моделей мира» до адекватного перевода ЕЯ-текстов (на естественном языке) между различными языками.
Онтологии выполняют функцию интеграции, обеспечивая общий семантический базис в процессах принятия решений и интеллектуального анализа данных, а также единую платформу для объединения разнообразных информационных систем,- говорит Антон Ермаков, руководитель группы цифровых инициатив компании Comindware.- Иными словами, онтологические модели становятся посредниками между бизнес-пользователями и информационной системой.
Для реализации онтологической модели используются графовые базы данных. Стоит отметить, что, несмотря на сравнительно молодой возраст этих баз данных (первая графовая БД, использующая модель ориентированного графа, появилась в 2007 г.), сегодня на рынке присутствуют различные их типы. В частности, HyperGraphDB использует модель мультиграфа, ArangoDB и OrientDB позиционируются как мультимодельные СУБД, а GraphX – это распределенный фреймворк для работы с графами в экосистеме Hadoop, использует вычислительный механизм Spark.
Все они обеспечивают поддержку ключевых характеристик онтологических моделей: децентрализованная структура данных, поддержка распределенных структур, связанность данных через семантический слой ИТ-архитектуры, хранение как структурированной, так и неструктурированной информации.
Так, графовые базы применяются в Facebook для гибкого и оперативного управления социальной сетью, в компании Amazon – для функционирования рекомендательного сервиса. В Сбере экспериментируют с прототипом бизнес-решения на основе сверхбольших графов, рассчитывая с их помощью решать задачи с миллиардами связей в интерактивном режиме: от поиска аффилированных лиц и организаций и до продуктовых рекомендаций.
Онтологии: общие и специализированные
Ключевой вопрос построения онтологии предметной области – задача классификации понятий частично. Для узкой области она решается еще на начальном этапе ее создания. Иначе дела обстоят с онтологиями верхнего уровня, которые содержат наиболее общие понятия всего реально мира, не относящиеся к строго ограниченному домену.

Источник: Онтологии в корпоративных системах. А.Я. Гладун, Ю.В. Рогушина, «Корпоративные системы, №1, 2006 г.
Тем не менее, к настоящему моменту уже создано около полутора десятков онтологий верхнего уровня, которые используются на практике. Например, онтология SUMO, разработанная институтом IEEE, преследует цель интеграции существующих онтологий в единую структуру, которая имела бы статус универсального стандарта. В ней реализована категоризация понятий на основе философского понятийного аппарата: вершиной является понятие «Сущность», сущности разделяются на физические и абстрактные и т. д.
Онтология BFO создавалась как верхний уровень для доменных онтологий в сфере науки. Сегодня основная цель BFO — поддерживать разработку онтологий предметной области с тем, чтобы способствовать координации работы различных групп специалистов, добиваться непротиворечивости и предотвращать избыточность онтологий.

Источник: база ГОСтов, allgosts.ru
Онтология BFO положена в основу российского ГОСТ Р 59798-2021 «Онтологии высшего уровня (TLO). Часть 2. Базисная формальная онтология (BFO)», который утвержден приказом № 1300-ст Федерального агентства по техническому регулированию и метрологии от 25 октября 2021 г. Он разработан с учетом основных нормативных положений международного стандарта ИСО/МЭК FDIS 21838-2:2021 «Информационные технологии. Онтологии высшего уровня (TLO). Часть 2. Базисная формальная онтология (BFO)» (ИСО/МЭК FDIS 21838-2:2021 «Information technology — Top-level ontologies (TLO) — Part 2: Basic Formal Ontology (BFO)», NEQ).
Российский стандарт описывает базовую формальную онтологию как ресурс для поддержки обмена информацией между разнородными информационными системами.
В НИВЦ МГУ им. Ломоносова идут работы по созданию ряда крупных ресурсов для информационного поиска: общественно-политического тезауруса, тезауруса русского языка РуТез, онтологии по естественным наукам и технологиям ОЕНТ, тезауруса Банка России, авиа-онтологии и др. Речь идет о лингвистических онтологиях для информационных систем в широких предметных областях.
Разнообразие предметных областей, для которых созданы эти ресурсы, доказывают универсальность предложенной модели лингвистической онтологии,- рассказывают руководители разработки Наталья Лукашевич и Борис Добров в статье «Проектирование лингвистических онтологий для информационных систем в широких предметных областях», «Онтология проектирования», том 5, №1, 2015 г.- То есть посредством такой модели можно описывав базовые свойства и отношения понятий, присутствующие в любой предметной области.
В ИППИ РАН разрабатывается онтология общего назначения, предназначенная для задач семантического анализа текста на любом естественном языке. Фактически система ЭТАП решает задачу извлечения смысла из текста на естественном языке. Благодаря семантическому анализу ЕЯ-текста, извлекается дополнительная информация, которая может быть использована для перевода. В целом, лингвистический процессор ЭТАП-3 – это компьютерная система, обладающая большим объемом знаний о естественном языке вообще, а также русском и английском языках, в частности. В результате система машинного перевода умеет переводить тексты с русского языка на английский и с английского на русский на базе механизма «Смысл – Текст».
Источник: ИППИ РАН
На базе онтологических моделей работает технология ABBYY Compreno. Предметная онтомодель позволяет выявлять сущности (названия организаций, предмет договора и его стороны, суммы по договору и т.д.) для построения фильтров и углубленной аналитики. Подключение пользовательских сущностей также происходит в фоновом режиме наряду с семантическим обогащением.
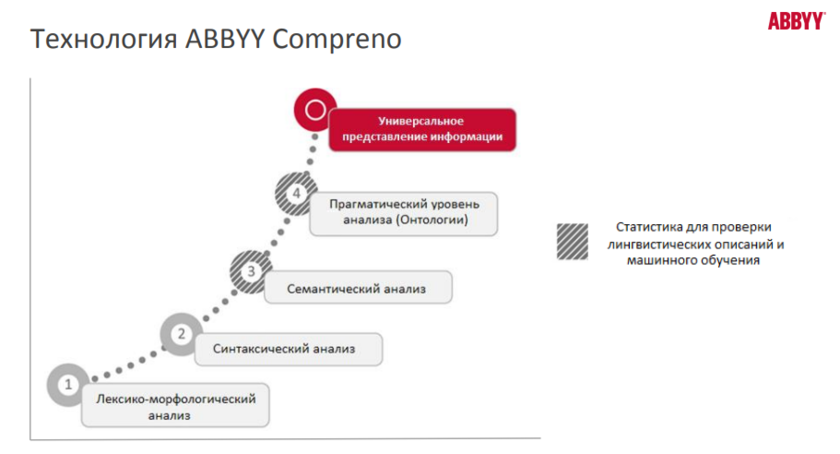
Источник: презентация «Перспективы ABBYY Compreno на российском рынке: бизнес-сценарии, преимущества, эффективность решений», Максим Михайлов, старший вице-президент компании ABBYY, 2015 г.
Например, для концерна «Росэнергоатом» реализован комплексный подход к повышению качества проектной документации при создании сложных технических объектов (например, АЭС): создана онтология ABBYY Compreno, описывающая понятийный аппарат предметной области (иерархия терминов и понятий, синонимичные конструкции, смысловые связи, типичные характеристики, диапазоны значений на основе имеющихся UML-описаний и экспертных знаний). Такой подход позволил организовать единое семантическое представление для различных описаний, используемых на сложных технических объектах: информационная модель объекта, спроектированная в виде чертежей, схем, 3D-объектов и т.д., проектная документация, а также документация на естественном языке.
Компания DataFabric создала универсальную платформу корпоративных онтологий DataFabric KGL, которая позволяет унифицировать доступ ко всем данным на предприятии с помощью платформы виртуализации данных с открытым исходным кодом. DataFabric KGL (или Logical DWH) предприятия реализуется на основе графовой (семантической) модели данных в терминологии предметной области. Она позволяет федеративно обращаться к гетерогенным данным из разных источников без необходимости их предварительного сбора, агрегации и хранения, рассказывают в компании: обращение к данным идет в терминологии предметной области через слой абстракции в виде бизнес-глоссария, без необходимости каких-либо операций на физическом уровне хранения данных.
Ядром платформы DataFabric KGL является база знаний предприятия, которая представляет собой онтологическую модель предметной области. Граф знаний включает все термины, сущности, понятия и определения, которые задействованы в бизнес-процессах предприятия. Все сущности связаны между собой отношениями, и все бизнес-сущности из графа знаний проецируются на реляционную структуру каждого из источников данных.
Возможности анализа данных на графах знаний позволяют: устанавливать связи между сущностями, искать признаки аффилированности между объектами, находить взаимосвязи событий и объектов, а также делать логические выводы, опираясь на реализованную в системе «модель мира». В частности, система способна самостоятельно порождать новые данные и устанавливать новые связи между данными на основании «картины мира», смоделированной через онтологическую модель предметной области.
Компания «ТриниДата» использует онтологии для создания цифровых двойников предприятий в рамках системы АрхиГраф.MDM. При этом под цифровым двойником подразумевается компьютерная модель внутренних процессов объекта и его взаимодействия с окружающей средой.
Онтологическая модель помогает справиться со структурой данных любой сложности, менять эту структуру по ходу работы с данными, – поясняет Сергей Горшков, руководитель компании «ТриниДата».- Во-первых, онтология позволяет работать с тысячами типов сущностей и разных связей между ними, делая это удобно, интуитивно, гибко, в том числе меняя структуру по ходу работы системы.
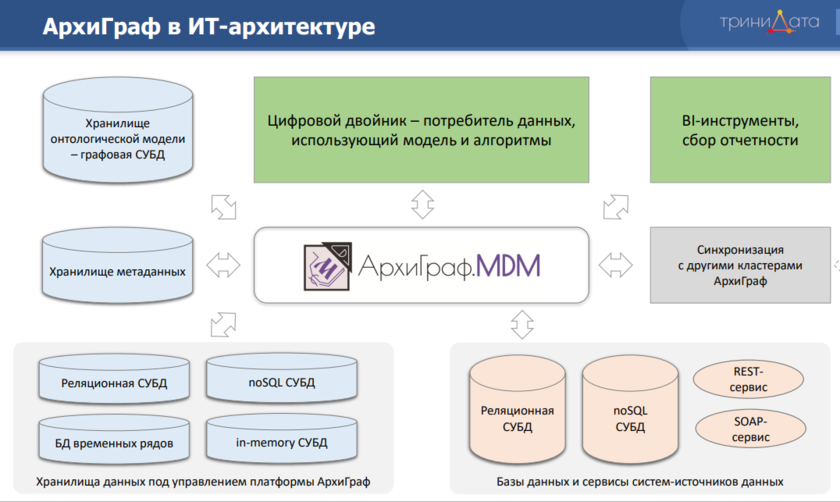
Источник: презентация «Сбор и моделирование данных для создания цифровых двойников», Сергей Горшков, директор компании «ТриниДата»
Платформа АрхиГраф.MDM поддерживает ряд следующих ключевых функций:
- Хранение онтологической модели всей корпоративной информации.
- Поддержка НСИ и мастер-данных, которые используют все остальные корпоративные приложения.
- Хранение любых транзакционных, операционных данных в кластерах СУБД под управлением платформы с доступом через единый интерфейс (виртуализация данных.)
- Доступ в режиме реального времени через единый API к данным любых сторонних хранилищ данных, включая СУБД унаследованного ПО, веб-сервисы современных корпоративных приложений и др. (логическая витрина данных).
Возможности платформы обеспечивают ее работоспособность в формате Open Platform Communications (OPC) на промышленных предприятиях, где программные технологии OPC предоставляют единый интерфейс для управления различными устройствами и обмена данными.
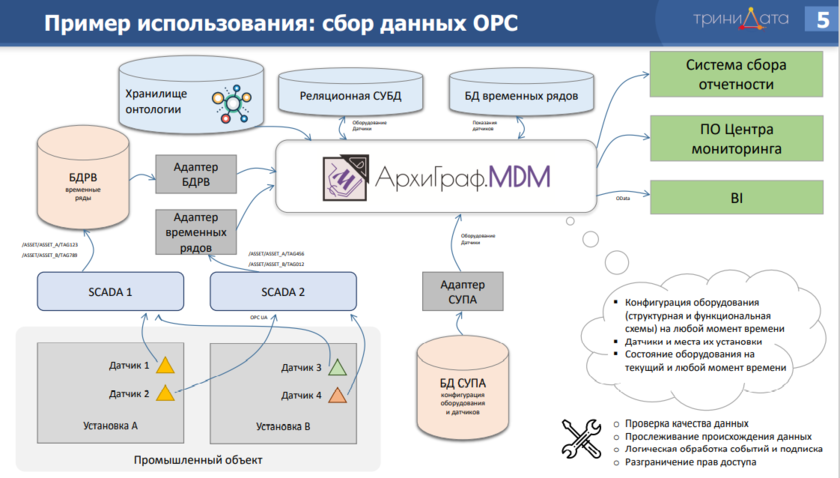
Источник: презентация «Сбор и моделирование данных для создания цифровых двойников», Сергей Горшков, директор компании «ТриниДата»
Онтологии для моделирования бизнес-процессов и управления корпоративными приложениями
Понятие онтологии и онтологического анализа вошли в процедуры моделирования бизнес-процессов, ведь описание бизнес-процесса — это, по сути, структурирование данных и знаний. Пример – онтология Process Specification Language (PSL), которая предназначена для автоматического обмена информацией о процессах, происходящих в различных производственных приложениях: планирование производства, электронный документооборот, управление проектами и т.д. Она утверждена в качестве международного стандарта ISO 18629.
Manufacturing Service Description Language (MSDL) – это язык онтологий для описания самого производства, которые включают пять уровней абстракции: поставщики, магазины, станочное оборудование, комплектующие и процессы.
На основе графовой базы и онтологической модели данных работает российская BPMS-система Comindware Business Application Platform. В компании подчеркивают: именно графовая база данных обеспечивает совместное хранение не только самих данных, но и отношений между ними, то есть семантические атрибуты. Таким образом, графовая база данных естественным образом интегрирует онтологическую модель бизнеса с данными. Более того, в графовой базе данных легко реализуется обработка косвенных связей, что, например, в реляционной СУБД вообще невозможно.
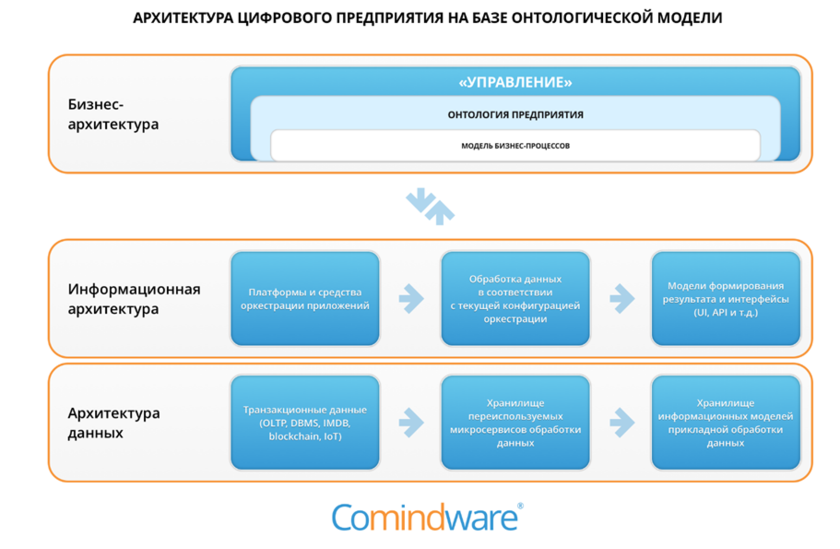
К тому же онтологии играют роль базиса для реализации Low-code инструментов процессного управления, ориентированных на сотрудников компании. Семантический слой КХД Онтологическая модель способна поддерживать целостность данных и обеспечивать их должное качество при изменении внешних и внутренних условий работы системы. По этим причинам, например, Сбер создает единую интегрированную модель данных в формализме семантического описания – таким способом обеспечивается доступ бизнес-подразделений не к «сырым», а качественным данным, а также реализуется гибкая интеграция данных в масштабе всей крупной организации.
Эту единую интегрированную модель данных в компании называют «Единый Семантический Слой» (ЕСС).ЕСС содержит мета-данные, которые обеспечивают эффективное управление процессами обработки данных в корпоративном хранилище данных (КХД), включая загрузку данных из высоконагруженных банковских систем на уровне нескольких десятков терабайт в сутки. Задача этого слоя – отделить потребителя от «сырых» данных и предоставить доступ к интегрированным, непротиворечивым и качественным данным ЕСС, что позволит исключить дублирование работ различных подразделений банка по data-интеграции, а также сделать работу с данными более понятной и прозрачной для пользователя.
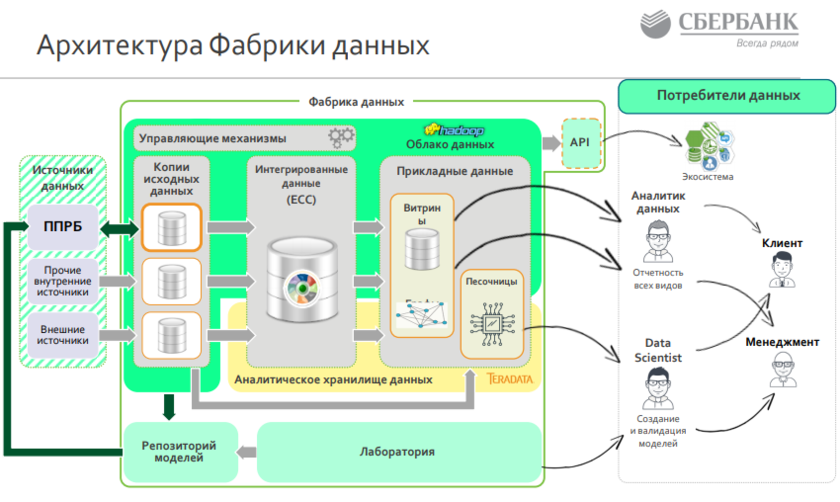
Источник: Сбербанк, 2018 г.
Семантический слой КХД также реализуется в аналитической платформе Loginom российской компании BaseGroup Labs. Платформа обеспечивает, в частности, развитую интеграцию данных, включая доступ к разнородным источникам (офисные приложения, «1C:Предприятие», СУБД, ERP-, CRM-системы, файлы, веб-сервисы), консолидацию данных в хранилище и удобный семантический слой хранилища данных для извлечения информации с применением привычных бизнес-терминов. Несколько лет назад в состав «Ростеха» («Объединенную приборостроительную корпорацию») вошла компания «Авикомп Сервисез», разработчика семантических процессоров семейства OntosMiner. В основу технологической архитектуры положена концепция использования предметных онтологий для управления обработкой текстов на естественном языке.
Решения OntosMiner ориентированы на поддержку стандартов онтологий консорциума W3C (в первую очередь, OWL), спецификации результатов обработки (XML, OWL, N3) и международных стандартов уровня TREC на этапах обработки текстов. В компании подчеркивают ориентацию на такие архитектуры проектируемых систем, которые обеспечивают гибкое комплексирование разнородных компонент за счет использования стандартов обмена информацией между ними.
Онтологический подход к проектированию систем семейства OntosMiner привел к созданию собственного инструментария онтологического инжиниринга. Это дает основания представителям «Авикомп Сервисез» утверждать, что система OntosMiner способна анализировать семантическую структуру любого вида данных. В перспективе на ее принципах могут быть созданы системы для анализа изображений и звука, а также для управления домашними устройствами («умный дом»), говорят в компании.
«Объединенная приборостроительная корпорация» намерена внедрять лингвистический процессор OntosMiner в проектах, связанных с построением сложных аналитических систем и систем мониторинга для широкого круга заказчиков. Кроме того, эти технологии рассматриваются как перспективные для проектов в области СУБД и интеграции разноформатных информационных хранилищ.
В целом, онтологические модели предметных областей – перспективное направление развития систем, связанных с анализом естественного языка. Например, такие модели, способные снимать многозначность слов, играют консолидирующую роль в целях формирования единого пространства описаний сложных технических объектов и систем. Например, проект такого рода на базе технологий ABBYY был выполнен в компании «Росэнергоатом».Сложные технические объекты, в частности, АЭС описываются различными способами. К наиболее значимым относятся:
- информационная модель объекта, спроектированная в инженерной системе в виде чертежей, схем, 3D-объектов, планов и т.д.;
- проектная документация, содержащая описание объекта и его частей на естественном языке;
- инженерная информационная модель (описывает параметры и связи между частями объекта).
Об объемах данных можно судить, например, по таким цифрам: 272814 файлов в 23982 папках составляют проектную документацию одного российского проекта АЭС. Требуемый объем файлового хранилища составляет 522 Гб.Для того чтобы обеспечить внутреннюю консистентность характеристик организационных структур, систем и компонентов АЭС, зафиксированных в проектной документации, была создана онтология, описывающая понятийный аппарат предметной области. (В качестве основы использовалась действующая онтология, которая используется в информационных моделях АЭС и САПР, применяемых для их разработки).
С помощью ПО ABBYY InfoExtractor вся документация преобразована в комплексную систему объектов, сущностей, значений и связей, что позволило идентифицировать возможные внутренние противоречия внутри массива идентифицированных характеристик. Таким образом, онтологии, с помощью которых можно представить согласованную систему понятий моделируемой области знаний, обретают все более широкую популярность у разработчиков. Однако на практике создание прикладных систем чаще всего требует комплексного использования различных методов представления знаний. И это еще одно «горячее» направление исследовательских работ, которые сегодня ведут различные научные коллективы.
Возможный вариант интеграции различных типов и моделей представления знаний
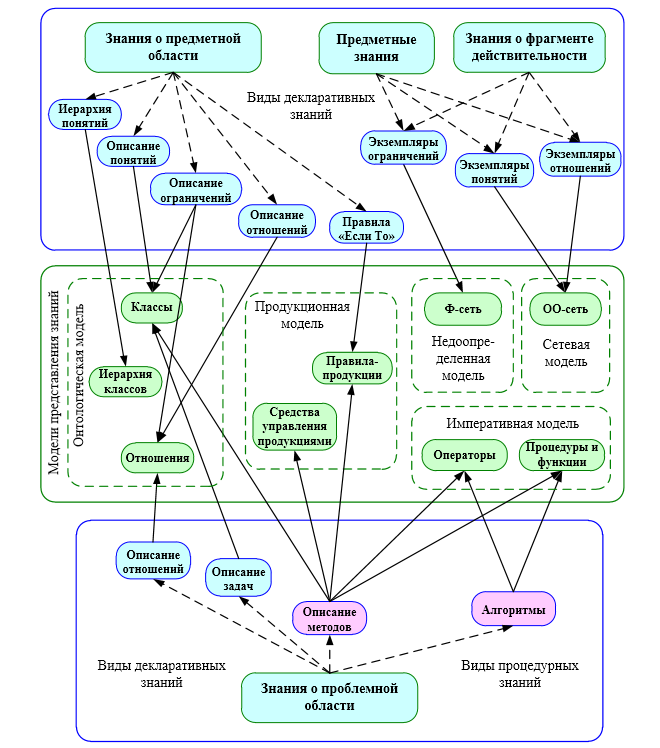
Источник: https://www.tadviser.ru/
|
|
Формализм онтологических моделей обеспечивает, действительно, очень гибкий и интуитивно понятный механизм для описания бизнес-процессов любой сложности и, что критически важно, их изменений,- подчеркивает Антон Ермаков из Comindware. |