 Интеллектуальная автоматическая обработка текстов на естественном языке – это та область программных решений, в которой традиционно работают многочисленные команды исследователей и разработчиков в самых разных странах. Действительно, применительно к корпоративному сектору речь идет о широком спектре возможностей обработки текстовых документов: от структурированных форм до текстов соглашений и переписки с клиентами на корпоративном форуме. Какие из этих возможностей сегодня стали рутинными общеупотребительными сервисами, а какие находятся на переднем фронте интеллектуальной обработки? Согласно оценкам аналитиков Центра компетенций «Искусственный интеллект» МФТИ, авторов альманаха «Искусственный интеллект» 2021, который вышел в свет в апреле, сегмент решений для обработки естественного языка (ЕЯ) Natural Language Processing (NLP) занимает в России 32,8% всего рынка ИИ.
Интеллектуальная автоматическая обработка текстов на естественном языке – это та область программных решений, в которой традиционно работают многочисленные команды исследователей и разработчиков в самых разных странах. Действительно, применительно к корпоративному сектору речь идет о широком спектре возможностей обработки текстовых документов: от структурированных форм до текстов соглашений и переписки с клиентами на корпоративном форуме. Какие из этих возможностей сегодня стали рутинными общеупотребительными сервисами, а какие находятся на переднем фронте интеллектуальной обработки? Согласно оценкам аналитиков Центра компетенций «Искусственный интеллект» МФТИ, авторов альманаха «Искусственный интеллект» 2021, который вышел в свет в апреле, сегмент решений для обработки естественного языка (ЕЯ) Natural Language Processing (NLP) занимает в России 32,8% всего рынка ИИ.
Для мирового рынка ИИ решения NLP – также значимый сегмент. По оценкам аналитиков компании Statista, темпы его ежегодного роста сохранятся на уровне 20,3% до 2026 г. По оценкам исследователей Frost&Sallivan, объем рынка технологий обработки естественного языка должен достичь к 2024 г. объема на уровне 43,5 млрд. долл.

Источник: Statista, август 2021 г.
О специфике современного этапа NLP-разработок говорил в 2008 г. известный российский ученый в области ИИ Владимир Хорошевский в своей статье в журнале «Искусственный интеллект и принятие решений»:
Современный (V) этап развития исследований и разработок в данной области характеризуется тем, что автоматической обработке подвергаются не искусственные (модельные) тексты, а реальные документы и, в общем случае, Web-контент; происходит обработка не единичных текстов, а мультиязычных коллекций документов; обрабатываемые документы содержат опечатки, орфографические ошибки, аграмматичности и другие реальные препятствия на пути к их правильной интерпретации.

Кроме того, подчеркивает специалист, целью обработки документа становится не просто получение внутреннего представления его смысла, а представление результатов в форматах, удобных для эффективного хранения знаний с учетом их постоянного пополнения и последующего использования.
Современные информационно-поисковые и информационно-аналитические системы работают с текстовой информацией в широких или неограниченных предметных областях, то есть областях, в состав которых входят тысячи разных классов сущностей, входящих между собой в неограниченные типы отношений. Поэтому, отмечает Наталья Лукашевич, профессор кафедры теоретической и прикладной лингвистики МГУ, в своей статье в журнале «Онтология проектирования» (том 5, №1, 2015 г.), характерной чертой современных методов обработки текстовой информации в таких системах стало минимальное использование знаний о мире и о языке, опора на статистические методы учета частотностей встречаемости слов в предложении, тексте, наборе документов, совместной встречаемости слов и т.п.
Этот подход принципиально отличается от того, как подобные операции выполняет человек: он выявляет основное содержание документа, основную тему и подтемы, и для этого обычно используется большой объем знаний о языке, о мире и об организации связного текста. Недостаток лингвистических и онтологических знаний (знаний о мире), используемых в системах автоматической обработки текстов, приводит к разнообразным проблемам, в первую очередь, нерелевантному распознаванию смысла текста и отдельных его деталей.
В таких условиях основное внимание исследователей и разработчиков сосредоточено на системах, предназначенных для извлечения данных из ЕЯ-текстов, системах обработки текстов класса Text Mining, помогающих выявлять в текстах полезную информацию, а также системах семантической классификации и кластеризации, позволяющих отнести конкретный текст к той или иной категории документов.
Например, основной проблемой для корректной работы системы чат-бота является верное определение темы обращения для того, чтобы выдать правильный ответ, поясняет Санжар Досов, ML-разработчик компании Globus: поставленную задачу хорошо решают подходы для классификации текста.
Классификация текстов
Задача классификации текстов имеет целью отнесение целевого текста в верный класс, который подходит по смыслу, и для ее решения задачи классификации требуется хотя бы минимальный разметка. Санжар Досов приводит пример такой разметки:
Будет большим плюсом, если имеется дополнительная разметка в качестве ключевых фраз в обращениях клиентов, которые встречаются в отдельно взятых классах,- добавляет эксперт.Он говорит, что сегодня используется два основных подхода к решению задачи классификации текстов:
- Регулярные выражения. Это специальный язык, используемый в некоторых программах обработки текста, который нацелен на поиск и осуществления манипуляций с подстроками в тексте. Сегодня этот подход относится к категории legacy, однако он достаточно часто используется, в том числе, в комбинации с алгоритмами машинного обучения.
- Нейронные сети.
Огромным плюсом нейросетевых подходов является то, что они имеют хорошую обобщающую способность и справляться с большим числом классов в задачах классификации,- говорит Санжар Досов. Яркий представитель данного подхода – популярная архитектура BERT, которая в последние годы демонстрирует наилучшие результаты в задаче классификации текстов.
Выявление сущностей в текстеВажный элемент анализа ЕЯ-текста – выявление в тексте именованных сущностей (Named Entity Recognition, NER): имена людей, торговые марки, географические названия, денежные суммы и т.д. В компании ISS, разработчике виртуального ассистента JINNEE, рассказывают:В каждой индустрии, даже у каждой компании есть большое количество своих сущностных имен. Например, у банков – типы и названия банковских карт (дебетовая, кредитная, с определенным кэшбеком), кредитов (потребительский, ипотека, для бизнеса), вкладов (рублевый, валютный и прочее). Все это чат-бот должен уметь понимать.
В продукте JINNEE есть предустановленные сущности, но, чтобы закрыть уникальные потребности любой компании, необходима адаптация модуля NER к конкретно ее задачам. Компания ISS пошла по пути обучения ботов лексике, соответствующей выбранным приоритетным отраслям. К ним сегодня относятся, в первую очередь, компании, работающие в сегменте массовых услуг: ритейл, e-commerce, сервисные компании.Из них также получаются отличные помощники HR-отделов со своим набором актуальных терминов: «отпуск», «зарплата», «страховка», «больничный» и т. д.»,- комментирует Андрей Куляшов, директор по развитию бизнеса компании ISS.По словам Станислава Ашманова, генерального директора компании «Наносемантика», в разрабатываемых решениях используется две технологии: словарное выделение именованных сущностей и машинное выявление сущностей NER.
Допустим, стоит задача определить сущность «населенный пункт» и выделить его название,- рассказывает Станислав Ашманов.- Если разрабатывается ассистент для железной дороги, то список станций конечен, и для определения станции в запросе проще использовать закрытый список, предоставленный заказчиком. Это и есть словарь.
Словари позволяют также задать синонимию названий (Санкт-Петербург – Питер) и нормализовать найденное в запросе название в любом падеже до именительного падежа для формирования запроса к сервису продажи билетов.
Если же речь идет о чит-чате (chit-chat), то есть возможности «поболтать» с машиной о том о сем), и разработчик ассистента хочет выделить в запросе любое произвольное название населенного пункта, хоть вымышленное или из литературного произведения, то здесь больше подойдет NER на машинном обучении, продолжает Станислав Ашманов, потому что эта технология устойчива к новым именованиям выделяемой сущности.
Санжар Досов из компании Globus отмечает, что для задачи NER, помимо нейросетевого инструментария, используется также подход, основанный на правилах языка (rule-based). Один из популярных rule-based подходов для русского языка реализован, например, в проекте NATASHA.Это не исследовательский проект, базовые технологии созданы для производства, подчеркивают в компании: в одном удобном API объединяется ряд библиотек, что позволяет решает базовые задачи NLP для русского языка: токенизация, сегментация предложений, встраивание слов, маркировка морфологии, лемматизация, нормализация фраз, синтаксический анализ, NER-теги, извлечение фактов.NER в проекте NATASHA

Источник: компания Globus
Подход для решения задачи NER, реализованный в проекте NATASHA, основан на легковесной нейросетевой модели и правилах русского языка. Такая комбинация подходов помогает успешно решать задачу,- отмечает Санжар Досо,- ведь при помощи rule-based подхода удается сделать морфологический разбор текста, что помогает выделять разные формы одних и тех же сущностей. Также rule-based подход позволяет успешно охватывать краевые случаи, а нейросетевой подход, в свою очередь, дает алгоритму хорошую обобщающую способность.
Распознавание текстаЕще один базовый механизм NLP-систем – оптическое распознавание текстов. Для большинства корпоративных NLP-систем оно реализует первую фазу работы с документами – преобразование текста на бумажном носителе в электронный вид. Сегодня функционал OCR вышел далеко за рамки трансформации бумажного документа в электронный аналог. Борьба идет за то, чтобы научить ИИ анализировать тексты: верифицировать содержащиеся в них сведения, обнаруживать возможные ошибки, выявлять данные, нужные для работы другим системам, и передавать их туда.
Компания Smart Engines представила в начале года систему интеллектуального автоматического распознавания всех страниц паспорта РФ. Программа сама находит на изображениях страницы паспорта и выполняет поиск на них штампов. Автоматически распознаются данные главного разворота паспорта с печатным и рукописным заполнением, все машинописные штампы о месте регистрации и сведения о ранее выданных паспортах. Для всех страниц паспорта ИИ автоматически определяет порядковый номер страницы в документе, а также распознает номер документа вне зависимости от того, напечатан он или нанесен методом лазерной перфорации.
Специалисты Smart Engines говорят, что за счет применения алгоритмов ИИ удалось решить большую проблему традиционных OCR-решений – необходимость ручной верификации результатов автоматического распознавания. Изображения с клиентскими данными ни в каком виде не передаются на ручной ввод внешним исполнителям или в сервисы коллективной работы, подчеркивают в компании.
Важно отметить, что данная система может использоваться для распознавания паспортных данных на фотографиях, сканах и в видеопотоке в мобильных приложениях, интернет-решениях и учетных информационных системах. При этом время распознавания данных основного разворота паспорта на 1 кадре на мобильном телефоне составляет 0,15 с.
Наша система может в реальном времени распознавать паспорт РФ, если пользователь показывает документ камере своего телефона страницу за страницей или автоматически проверить, что в заявке от клиента на фотографиях или скан-образах присутствуют все необходимые страницы одного паспорта, и распознать нужные данные,- комментирует Владимир Арлазаров, к.т.н., генеральный директор Smart Engines.- Выполняя распознавание, программа рассматривает весь паспорт как единый комплект данных, разнесенных на разные страницы.
Летом Smart Engines выпустила систему распознавания первичной бухгалтерской и финансовой документации на мобильных телефонах с таким же высоким качеством, не требующим ручной верификации. Система автоматически классифицирует и распознает счета-фактуры, ТОРГ-12, УПД, товарно-транспортные накладные, акты и счета на оплату, а также обеспечивает ввод информации из документов и форм в ERP-систему или любую другую учетную информационную систему с возможностью проверки комплектности и кросс-верификации данных в рамках одного комплекта.
Как рассказывают в компании, распознавание первичного документа на современном телефоне в мобильном приложении занимает 1-3 с на страницу, а в серверном режиме на 32-ядерном высокопроизводительном компьютере (HPC) без применения GPU скорость распознавания при потоковом сканировании в традиционных центрах ввода может достигать 600 страниц в минуту.
Теперь бизнес может перейти на новый уровень мобильности, отказавшись от использования потоковых сканеров для получения изображений и специальных рабочих станций или серверов для распознавания первичных документов,- рассказывает Владимир Арлазаров.- Сотрудники могут выполнять сканирование и извлечение данных мобильным телефоном непосредственно при приеме документов от контрагентов.
Программная платформа CORRECT компании «ТКсэт» также решает задачу автоматизации процедур ввода бухгалтерских, кадровых, транспортных, юридических и иных документов в учетные системы заказчика: извлекает информацию из множества различных типов документов по заранее настроенным шаблонам, выполняет математические проверки, а также проверки по глобальным справочникам (ЕГРЮЛ/ЕГРИП, адреса, имена руководителей и т.д.), и сопоставляет полученные сведения с локальным справочником номенклатур.
В компании рассказывают, что архитектурно решение CORRECT базируется на двух OCR и имеет собственную методику сопоставления номенклатур, которая учитывает ассортимент SKU на складе. Поддерживается также функционал полнотекстового распознавания документов, чтения штрих-кодов, QR-кодов, проверки наличия печатей и подписей. Через открытый API платформа может быть интегрирована с различными учетными системами («1С», SAP, Oracle, Dynamics и др.), RPA-платформами (Electoneek, Sherpa, Lexema и др.), краудсорсинговыми платформами (Яндекс.Толока). Программное обеспечение CORRECT может устанавливаться на площадке заказчика, либо предоставляться как сервис SaaS с постраничной оплатой.
Распознавание счета-фактуры

Источник: компания «ТКсэт»
Интеллект – это не только распознавание документов, но и работа с классификацией, обучением на исторических данных. С таким подходом получится собрать всю общность данных, получить результат, сделать скидку на вероятность и ускорить процесс заведения документа в ИС,- отмечает Виталий Астраханцев, евангелист AI-направления компании Directum.
Особенную важность эти аспекты приобретают при работе с большими объемами разнообразной текстовой информации, например, для задач электронного архива.
Например, для компании «УК Сибантрацит» на базе системы Directum была осуществлена автоматизация финансового архива с интеллектуальной обработкой входящих первичных документов (актов, товарных накладных, транспортных накладных, счетов-фактур и др.).
Большой объем входящих документов удалось направить на простое и удобное занесение и добавление в финансовый архив,- говорит Виталий Астраханцев.
При этом точность классификации вида документов достигла 97%, а полнота извлечения атрибутов из поступающих документов – 85%.
Платформа ABBYY FlexiCapture разработана для сбора информации из документов различных типов: текстов писем, вложений, электронных документов, фотографий, сканов. Алгоритмы, реализованные в FlexiCapture, дают возможность распознать и классифицировать документы, извлечь и проверить корректность данных, передать их в корпоративную информационную систему.
Например, оператор связи Tele2, который развивает каналы самообслуживания, позволяет новым клиентам удаленно открывать SIM-карты с помощью терминалов с распознаванием лиц и документов, удостоверяющих личность. В этом решении технологии ABBYY автоматически извлекают паспортные данные и отправляют их на проверку оператору.
А компания ЛАНИТ реализовала для «НПО Энергомаш» на базе своей СЭД/ECM системы LANDocs функционал полнотекстового поиска по множеству информационных систем производственного предприятия. Система корпоративного поиска подключается к файловому хранилищу, системе электронного документооборота, ERP-системе и PLM-системе.
Если специалист заказчика введет название изделия, он получит всю релевантную информацию: из PLM-системы – о самом изделии, из ERP-системы – финансовые показатели, связанные с расходами,- рассказывает Александр Родионов, директор департамента управления документами, руководитель Центра инноваций ЛАНИТ.
Стоит отметить, что задача распознавания популярных шрифтов текстовых документов, – это массово востребованное решение. А вот такие задачи, как, например, распознавание шрифта по ГОСТу на технологической схеме, – являются гораздо более сложными. Специалисты «Наносемантики» замечают, что качество работы продукта, ориентированного на массового потребителя, в этой ситуации показывает низкое качество, здесь требуется кастомизация.
Один из важнейших элементов решений по выявлению данных из ЕЯ-текстов – гибкость программной системы в настройке на новые типы документов.
Виталий Астраханцев из Directum рассказывает, как эта задача решается в системе интеллектуальных сервисов Directum Ario:
Благодаря механизмам дообучения классификаторов и механизмам авторазметки можно выгрузить карточки документов и на их основании сделать проект разметки и обучить модели извлечения фактов для нового вида документа. Мы также работаем в направлении кластеризации выгруженных документов с целью подготовки обучающей выборки и повышения качества итоговых моделей. В Directum RX, с точки зрения интеллектуального распознавания, созданы практически все условия для того, чтобы просто и быстро вводить в работу новые виды и новые формы документов.
Что еще научились извлекать из ЕЯ-текстов системы NLP? Достаточно давно развиваются решения по оценке тональности (эмоциональной окраски) текстовых сообщений. Такие решения находят применение, в первую очередь, для анализа негативных и позитивных откликов клиентов на форумах, сайтах, соцсетях.
В мае на межведомственной конференции «Искусственный интеллект на службе полиции» разработчики из Вятского госуниверситета представили систему автоматического распознавания точки зрения автора текста на русском и английском языках.
Специфические задачи обработки ЕЯ-текстов
Отдельный сегмент ИИ-решений связан с адекватным представлением, так называемого транскрибированного текста, то есть текстовой копией аудиосообщения. Функционал преобразования Speech-to-Text становится все более популярным и выходит на уровень массовых услуг. Например, подписчики Telegram Premium могут воспользоваться кнопкой, чтобы отправить запрос на перевод конкретного голосового сообщения в текст (для этого используется оборудование Google, как пояснил Павел Дуров).
Одна из интересных задач этого класса связана с расстановкой знаков препинания в финальном тексте. Для ее решения требуется нетривиальный анализ аудиофрагмента: специфика пауз в словах, характер изменения интонаций и т.п. Разработчики Сбера создали свою GPU-based систему SmartSpeech для распознавания речи, с уникальными декодером и акустической моделью. Эта технология обеспечивает, во-первых, автоматическое определение спикера по голосу, и, во-вторых, автоматически определяет паузы, конец высказывания, эмоции спикера и расставляет знаки препинания в расшифровке беседы в режиме реального времени.
Система SmartSpeech используется, в частности, в решениях видеоконференцсвязи, которые выводит на рынок Сбер: в любой момент встречи участник конференции может скачать полный текст разговора, причем, в тексте диалогов можно осуществлять поиск по заметкам.
Облачная платформа Yandex Cloud весной обновила Yandex SpeechKit — сервис для синтеза и распознавания речи на базе машинного обучения. Теперь при переводе голоса в текст сервис автоматически расставляет необходимые знаки препинания. Распознанный нейросетью текст максимально приближен к литературному, говорят в компании.
Новая функция Yandex SpeechKit, которая получила название «Пунктуатор», работает как при распознавании в реальном времени для сценариев с голосовыми помощниками, так и при распознавании предзаписанных аудиофайлов. Пунктуатор использует две последовательно работающие модели машинного обучения. Первая переводит голос в текст, вторая расставляет знаки препинания в соответствии с нормами русского языка.
На основе базовых технологий выявления данных из ЕЯ-текстов различной природы реализуются современные решения для широкого спектра корпоративных задач:
- Регистрация входящей документации
- Полнотекстовое распознавание
- Ввод документов в информационные системы
- Работа с внутренней документацией (оперативное извлечение информации из приказов, распоряжений и других нормативных документов для удобного доступа, сверки и поиска по ним)
- Сравнение документов (различных версий одного документа)
- Обработка проектно-сметной документации (автоматическое сравнение данных из проектно-сметной документации с данными в САПР)
- Классификация входящих запросов (автоматизация классификации обращений, определения важности запроса и поиска готового ответа, что используется, в первую очередь, в системах техподдержки пользователей, консультирования клиентов, контактных центрах и т.д.).
- Интеллектуальный поиск (классификация, извлечение объектов и связанных с ними фактов, анализ тональности)
Например, Naumen Enterprise Search – это единая поисковая система, которой могут пользоваться все сотрудники компании. Поиск можно вести не только среди электронных документов, но и в архивах изображений и видео, электронных письмах и презентациях, текстах заявок, электронных книгах и веб-страницах, а также корпоративных системах обработки информации: CRM, ERP, электронная почта, НСИ-системы, вики, таск-трекеры, системы сбора и хранения показаний приборов учета и др.
Механизм ABBYY Intelligent Search, как утверждают в компании, осуществляет корпоративный поиск по всем источникам данных, причем, поиск идет по смыслу, а не по ключевым словам.

Смысловой поиск поддерживает также RCO Zoom — специализированная поисковая система, сочетающая функционал традиционных поисковых систем и анализа информации. Система использует методы автоматизации онтологического инжиниринга для извлечения знаний из текста, что позволяет реализовывать, как контекстный, так и объектный текстовый поиск. Поддерживается морфология и синтаксис русского и английского языков, возможность работы с грифованной информацией. Благодаря высокопроизводительной и независимой базе данных, систему можно использовать в качестве высоконадежного хранилища документов.
Система RCO Zoom интегрирована с библиотекой RCO Fact Extractor SDK, предназначенной для извлечения фактов из ЕЯ-текстов. А интерфейс для Python позволяет реализовывать всевозможные надстройки для решения разноплановых задач помимо хранения и поиска: от нахождения информационных дублей документов до их классификации и кластеризации.
Понимание текста
С практической точки зрения, технологии и системы понимания ЕЯ-текстов (Natural Language Understanding, NLU) связывают вместе факты, события, сущности, которые встречаются в тексте, конкретными отношениями. Вместе факты и связи между ними формируют единую картину того, что описывается в тексте. Это и есть некоторое «машинное понимание» текста, которое позволяет, например, давать правильные ответы на вопросы, связанные с этим описанием. Так, компания «Наносемантика» использует машинное обучение для задачи NLU. Она предлагает готовую платформу-конструктор, в рамках которой можно получить качественные ML-модели, даже не будучи специалистом по Data Science.
Технологическими важными операциями для NLU является разрешение часто встречающихся лингвистических конструкций, например:
- эллипсис – восстановление пропущенных слов, которые человек легко восстанавливает, исходя из понимания прочитанного. Например, в предложении «Выручка компании в первом квартале выросла на 20%, а в следующем – на 30%», пропущены слова «квартале» и «выросла»;
- анафора – местоимение заменяет существительное. Например, во фразе «Рубль продолжает укрепляться по отношению к доллару, вчера он вырос на 1 руб.», местоимение «он» заменяет существительное «рубль»;
- омонимия – многозначное толкование слова. Например, курс может быть у валюты, корабля в море и учебного материала.
Умная обработка выявленных в тексте сущностей подразумевает превращение данных в знания (факты, связанные с персонами или теми или иными объектами, определенными связями). Например, этот механизм реализован в решении ABBYY InfoExtractor SDK.

При этом речь идет об извлечении не просто именованных сущностей (NER), а всевозможных данных из неструктурированных текстов.
Ключевая особенность извлечения сущностей с целью последующего превращения их в факты в этом решении – использование онтологического подхода. Это означает, что в ходе разбора ЕЯ-текста строится семантическая иерархия понятий, представленная в виде дерева. Это дает возможность избежать неоднозначных трактовок. Например, слово «управление» можно трактовать как департамент компании, а можно как действие. Благодаря тому, что это слово в разных ветках представлено по-разному, система может подобрать нужные слова в зависимости от контекста фразы.

Онтология занимается тем, что создает прагматический слой анализа текста, определяет терминологию для конкретной предметной области и правила извлечения нужных объектов. В итоге вся информация представляется в нужном заказчику виде,- рассказывают в компании ABBYY.
При этом данные для наиболее распространенных задач входят в состав базовых онтологий программного решения, а для других конкретных отраслевых тем может потребоваться разработка соответствующей отраслевой онтологии с нуля.
К этому добавляется машинное обучение с учителем на размеченной обучающей выборке, что в результате обеспечивает быстрый старт работы по извлечению данных из текстов на основании некоторой онтологической модели предметной области.

В качестве примера приведен семантический разбор предложения:
Вопросы любви и смерти не волновали Ипполита Матвеевича Воробьянинова, хотя этими вопросами, по роду своей службы, он ведал с 9 утра до 5 вечера ежедневно, с получасовым перерывом для завтрака.

Источник: блог ABBYY на habr.ru
На базе этих технологий Сбербанк создал систему мониторинга новостного потока. Это решение автоматически анализирует содержание сообщений о банках-контрагентах на русском языке и находит в них разные рисковые факторы. Через модели ABBYY в реальном времени проходит весь объем новостей о более, чем тысяче банков-контрагентов, но в досье автоматически попадают только полезные данные, с точки зрения рисков.
RCO Fact Extractor SDK – это технология выявления фактов с использованием синтактико-семантического анализа текста, разработанная компанией RCO. Библиотека производит лингвистический разбор текста с учетом грамматики и семантики языка и предоставляет программный интерфейс для считывания результатов разбора и использования другими программами, например, для визуализации полученных данных, построения отчетов и таблиц, организации поиска по объектам и т.д.
Результатом анализа текста являются выделенные из текста сущности – наименования организаций, персон, географические объекты, различные символьно-цифровые конструкции (номера автомобилей или полисов страхования, адреса), а также классы сущностей. Кроме того, выявляется сеть синтактико-семантических отношений между сущностями текста, а также структуры данных, описывающие упомянутые в тексте события и факты.
Библиотека RCO Fact Extractor SDK универсальна: ее можно настроить на работу с разными предметными областями и даже с разными языками. Более того, она может помочь в составлении онтологий предметной области. Всевозможные надстройки над базовой библиотекой позволяют решать разные задачи, рассказывают в компании: от нахождения информационных дублей (плагиата) и построения смыслового портрета документа и до обезличивания персональных данных в текстах.
OntosMiner — это лингвистический процессор (разработчик – компания «Авикомп Сервисез», в настоящее время входит в состав «Объединенной приборостроительной корпорации»), который обеспечивает распознавание в ЕЯ-текстах именованных сущностей и семантических связей между ними (факты), а также умеет определять общую тональность документа. Лингвистический процессор OntosMiner проводит интеллектуальную обработку текста с использованием онтологий и словарей, доступных для редактирования пользователем, а также специальных эвристик.
В рамках проекта Ontos была, в частности, разработана система поддержки онтологических словарей OntoDix, где словарные входы до погружения в БЗ обрабатываются диалоговым модулем синтаксического анализа словосочетаний. А результаты обработки всех словарных статей, после «утверждения» пользователем, компилируются в эффективный автомат, подключаемый в качестве словарного ресурса к соответствующим системам семейства OntosMiner на этапе исполнения.
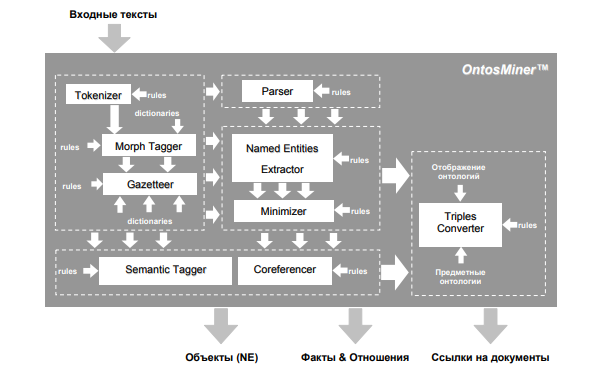
Источник: В.Ф. Хорошевский. Пространства знаний в сети Интернет и Semantic Web. Часть 3//Искусственный интеллект и принятие решений, №1/2012 г.
Ontosminer активно используется для анализа и систематизации больших массивов переписки, корпоративных документов и новостных публикаций в госорганах. Так, в одном из федеральных ведомств эта система обрабатывает в автоматизированном режиме анализом и классификацией входящей корреспонденции объемом более 1000 обращений в день по тысяче категорий.
Перспективные направления
Большие ожидания связаны с автоматической генерацией ЕЯ-текстов. Они в большой мере связаны с достижениями алгоритма GPT-3, разработанного лабораторией OpenAI. Он умеет на базе нескольких примеров выполнять множество заданий, прямо или косвенно связанных с текстом (на английском языке): писать стихи и новости, переводить, давать описания, разгадывать анаграммы, структурировать информацию.
Модель, которая использует 175 млрд. параметров, обучена на 570 Гб текстовой информации. В массив для обучения вошли данные открытой библиотеки Common Crawl, «Википедия», датасеты с книгами, тексты с сайтов WebText. Размер обученной модели составляет около 700 Гб. Прошлым летом OpenAI открыла частный доступ к инструментам для разработчиков (API) и модели GPT-3, и постепенно подключает к ней все больше разработчиков.
Через полгода после появления GPT-3 компания Google представила языковую модель на 1 трлн. параметров, а еще через полгода объявила об их использовании в своих продуктах. А Microsoft совместно с Nvidia разработала языковую модель Megatron-Turing Natural Language Generation с 530 млрд. параметров, которая также предназначена для генерации естественной речи и в три раза больше GPT-3.
При этом Microsoft тесно сотрудничает с OpenAI. Летом 2021 года компании представили Copilot для GitHub, который позволяет разработчикам автоматизировать некоторые процессы написания кода. Спустя четыре месяца после запуска компании отчитались, что инструмент помог написать около 30% нового кода, размещенного на площадке.
Что касается практических применений этих технологий, то, пожалуй, наиболее впечатляющих успехов они достигли в области когнитивных противоборств для создания пропагандистских информационных пакетов. Как отмечает Елена Ларина, ведущий аналитик Института системно-стратегического анализа, член сообщества практиков конкурентной разведки, в своей статье «Новая среда обитания» (журнал «Свободная мысль», №3, 2021), начиная с второй половины 2019 г. для этих целей стали активно использоваться, так называемые киберписатели, созданные в виде приложения GPT-2, а затем GPT-3. Самая крупная языковая модель разработана в Китае: модель WuDao 2.0 использует 1,75 трлн. параметров. Российский лидер – YaML, языковая модель, разработанная в компании «Яндекс»,с 13 млрд. параметров. На ее основе разработчики собрали демонстрационный сервис «Балабоба», где пользователи могут попросить нейросеть «додумать» предложение или целые куски текста, используя лишь небольшую вводную фразу.
Еще об одном перспективном направлении говорит Виталий Астраханцев из компании Directum:
Сегодня на рынке нет инструментов, которые могут обучаться на действиях пользователей. И мы работаем над этим. Наша цель – создать интеллект, который будет постепенно накапливать данные для обучения и по достижении необходимого объема построит модели и начнет помогать пользователю.
Иными словами, на старте проекта внедрения ИИ снизит затраты на запуск и научит систему заказчика тому, как работают пользователи. А после обучения система сама начнет заполнять данные и помогать в принятии решений: программные инструменты будут собирать статистику с серверов заказчиков о том, как пользователи заполняют определенные поля, как принимают решения.
Периодически ИИ-инструменты будут корректировать внесенную информацию и строить модель распознавания. Если модели будут соответствовать заданным критериям, то будут использоваться в работе и регулярно улучшаться. Если модели не соответствуют заданным критериям, значит мы будем продолжать собирать данные, пока не достигнем результата и не сможем дать максимальный эффект пользователям системы,- предполагает Виталий Астраханцев.
Источник: https://www.tadviser.ru/