
 В обучении с подкреплением (Reinforcement Learning) часто используется любопытство в качестве мотивации для ИИ. Заставляющее его искать новые ощущения и исследовать окружающий мир. Но жизнь полна неприятных сюрпризов. Можно упасть с обрыва и с точки зрения любопытства это всегда будут очень новые и интересные ощущения. Но явно не то, к чему надо стремиться. Разработчики из Berkeley перевернули задачу для виртуального агента с ног на голову: главной мотивирующей силой сделали не любопытство, а наоборот — стремление всеми силами избегать любой новизны. Но “ничего не делать” оказалось сложнее, чем кажется. Будучи помещенным в постоянно меняющийся окружающий мир, ИИ пришлось обучиться сложному поведению, чтобы избегать новых ощущений. Обучение с подкреплением (Reinforcement Learning) делает робкие шаги в сторону создания сильного ИИ.
В обучении с подкреплением (Reinforcement Learning) часто используется любопытство в качестве мотивации для ИИ. Заставляющее его искать новые ощущения и исследовать окружающий мир. Но жизнь полна неприятных сюрпризов. Можно упасть с обрыва и с точки зрения любопытства это всегда будут очень новые и интересные ощущения. Но явно не то, к чему надо стремиться. Разработчики из Berkeley перевернули задачу для виртуального агента с ног на голову: главной мотивирующей силой сделали не любопытство, а наоборот — стремление всеми силами избегать любой новизны. Но “ничего не делать” оказалось сложнее, чем кажется. Будучи помещенным в постоянно меняющийся окружающий мир, ИИ пришлось обучиться сложному поведению, чтобы избегать новых ощущений. Обучение с подкреплением (Reinforcement Learning) делает робкие шаги в сторону создания сильного ИИ.

И хотя пока все ограничивается очень низкими размерностями, буквально единицы, в которых приходится действовать виртуальному агенту (желательно разумно), время от времени появляются новые идеи как усовершенствовать обучение искусственного интеллекта.
Но усложняются не только алгоритмы обучения. Окружения тоже становятся сложнее. Большинство окружений для reinforcement learning очень простые и мотивируют агента исследовать окружающий мир. Это может быть лабиринт, который надо весь обойти, чтобы найти выход, или компьютерная игра, которую надо пройти до конца.

Но в долгосрочной перспективе живые существа (разумные и не очень) стремятся не только исследовать окружающий мир. Но и сохранить все хорошее, что есть в их короткой (или не очень) жизни.
Это называется гомеостаз — стремление организма сохранить постоянное состояние. В том или ином виде это свойственно всех живым существам. Разработчики из Berkeley приводят такой странный пример: все достижения человечества, по большому счету, созданы для защиты от неприятных сюрпризов. Для защиты от все возрастающей энтропии окружающей среды. Мы строим дома, где поддерживаем постоянную температуру, защищенную от перепадов погоды. Используем медицину, чтобы быть постоянно здоровыми и так далее. С этим можно поспорить, но в этой аналогии действительно что-то есть.
Ребята задались вопросом — что будет, если главной мотивацией для ИИ сделать попытку избегать любой новизны? Минимизировать хаос в качестве целевой функции обучения, другими словами. И поместили агента в постоянно меняющийся опасный мир.
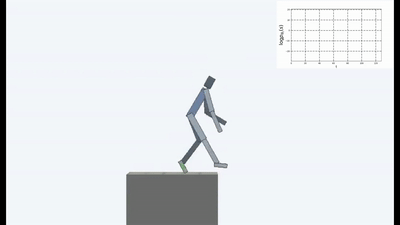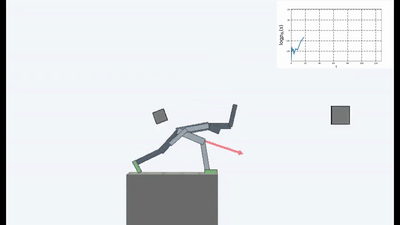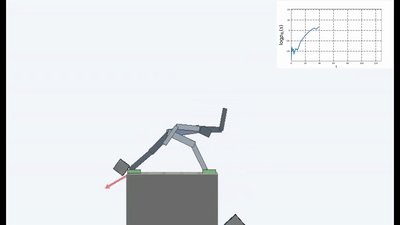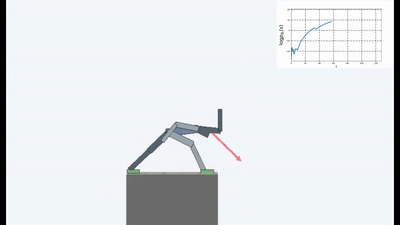
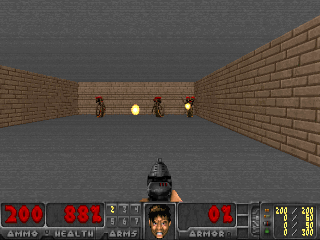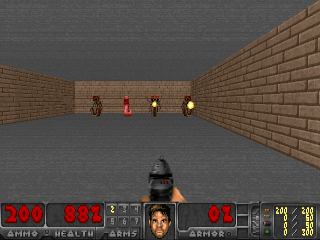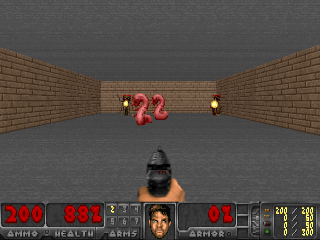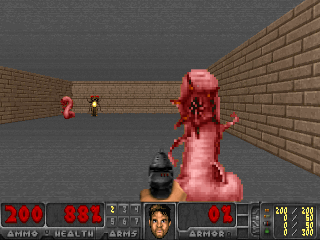
Результаты оказались интересными. Во многих случаях такое обучение превзошло обучение на основе любопытства, и чаще всего по качеству приближалось к обучению с учителем. То есть к специализированному обучению по достижению конретной цели — выиграть в игре, пройти лабиринт.
Это конечно логично, потому что если вы стоите на разрушающемся мосту, то чтобы продолжать на нем находиться (поддерживать постоянство и избегать новых ощущений от падения), вам необходимо постоянно отходить от края. Бежать изо всех сил, чтобы продолжать стоять на месте, как говорила Алиса.

И на самом деле в любом алгоритме обучения с подкреплением присутствует такой момент. Потому что смерти в игре и быстрое окончание эпизода штрафуются отрицательной наградой. Или, в зависимости от алгоритма, снижением максимальной награды, которую агент мог бы получить, если бы не падал постоянно со скалы.
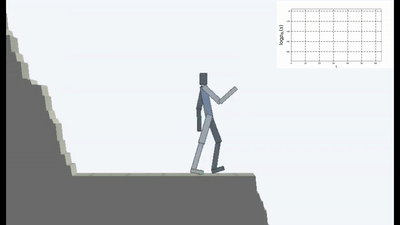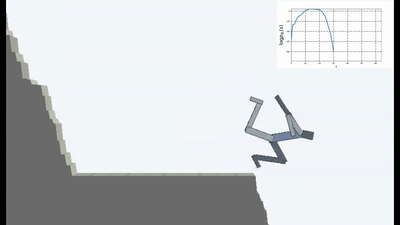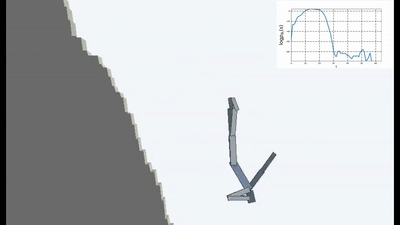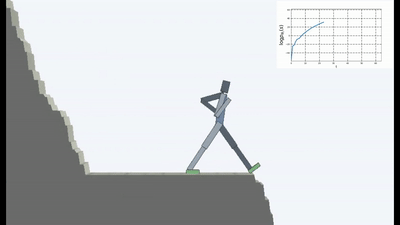
Но именно в такой постановке, когда у ИИ нет никаких других целей, кроме как стремления избегать новизны, вроде как в обучении с подкреплением применено впервые.
Что интересно, с такой мотивацией виртуальный агент научился проходить многие игры, в которых есть цель для выигрыша. Например, тетрис.

Или окружение из Doom, где надо уворачиваться от летящих огненных шаров и стрелять в приближающихся противников. Потому что многие задачи можно сформулировать как задачи по сохранению постоянства. Для тетриса это стремление сохранить поле пустым. Экран постоянно заполняется? О боже, что же случится, когда он заполнится до конца? Не-не, такого счастья нам не надо. Слишком сильное потрясение.
С технической стороны это устроено довольно просто. Когда агент получает новый state, он оценивает насколько это состояние ему знакомо. То есть насколько новое состояние входит в распределение state, которые он посетил ранее. Чем в более знакомое state агент попадает, тем большую получает награду. И задача обучения policy (это все термины из Reinforcement Learning, если кто не знает) заключается в выборе таких действий actions, которые приводили бы к переходу в максимально знакомый state. При этом каждый полученный новый state служит для обновления статистики знакомых состояний, с которой сравниваются новые состояния.
Что интересно, в процессе ИИ самопроизвольно обучился пониманию тому, что новые state влияют на то, что считать новизной. И что достигнуть знакомых состояний можно двумя способами: либо перейти в уже известное состояние. Либо перейти в такое состояние, которое обновит само понятие постоянства/знакомости окружения, и агент окажется в новом, сформированном его действиями, знакомом state.
Это заставляет агента предпринимать сложные скоординированные действия, лишь бы ничего в жизни не делать.
Парадоксальным образом это приводит к аналогу любопытства из обычного обучения, и заставляет агента исследовать окружающий мир. Вдруг где-то есть место, еще более безопасное, чем здесь и сейчас? Там можно будет полностью предаться лени и абсолютно ничего не делать, избегая тем самым любых проблем и новых ощущений. Не будет преувеличением сказать, что подобные мысли наверно приходили в голову любому из нас. А для многих это является настоящей движущей силой в жизни. Хотя в реальной жизни никому из нас не приходилось сталкиваться с заполняющимся до верха тетрисом, конечно.
Если честно, это запутанная история. Но практика показывает, что это работает. Исследователи сравнили этот алгоритм с лучшими представителями на основе любопытства: ICM и RND. Первый представляет собой эффективный и ставший уже классическим в обучении с подкреплением механизм любопытства. Агент стремится не просто к новым незнакомым и поэтому интересным состояниям. Незнакомость ситуации в подобных алгоритмах оценивается по тому, может ли агент ее предсказать (в более ранних были буквально счетчики посещенных состояний, но сейчас все свелось к интегральной оценке, которую дает нейронная сеть). Но в таком случае шевелящаяся листва на деревьях или белый шум по телевизору обладали бы бесконечной новизной для такого агента, и вызывали бы бесконечно чувство любопытства. Потому что он никогда не сможет предсказать все возможные новые state в полностью случайной окружающей среде.
Поэтому в ICM агент стремится только к тем новым state, на которые он может повлиять своими действиями. ИИ может повлиять на белый шум на экране телевизора? Нет. Значит неинтересно. А может повлиять на мяч, если его сдвинуть? Да. Значит играть с мячом интересно. Для этого в ICM используется очень классная идея с Inverse Model, с которой сравнивается Forward Model. Подробнее в оригинальной работе.
RND представляет собой более новую разработку механизма любопытства. Которая на практике превзошла ICM. Если коротко, нейросеть пытается предсказать выходы другой нейросети, которая инициирована случайными весами и никогда не меняется. Предполагается, что чем более знакомая ситуация (подающаяся на вход обеим нейросетям, текущей и случайно инициированной), тем чаще текущая нейросеть сможет предсказывать выходы случайно инициированной. Я не знаю, кто все это придумывает. С одной стороны хочется пожать руку такому человеку, а с другой дать пинка за такие извращения.
Но так или иначе, а обучение на идее сохранения гомеостаза и попытке избегать любой новизны, во многих случаях на практике достигло лучшего итогового результата, чем обучение на основе любопытства на основе ICN или RND. Что отражено на графиках.
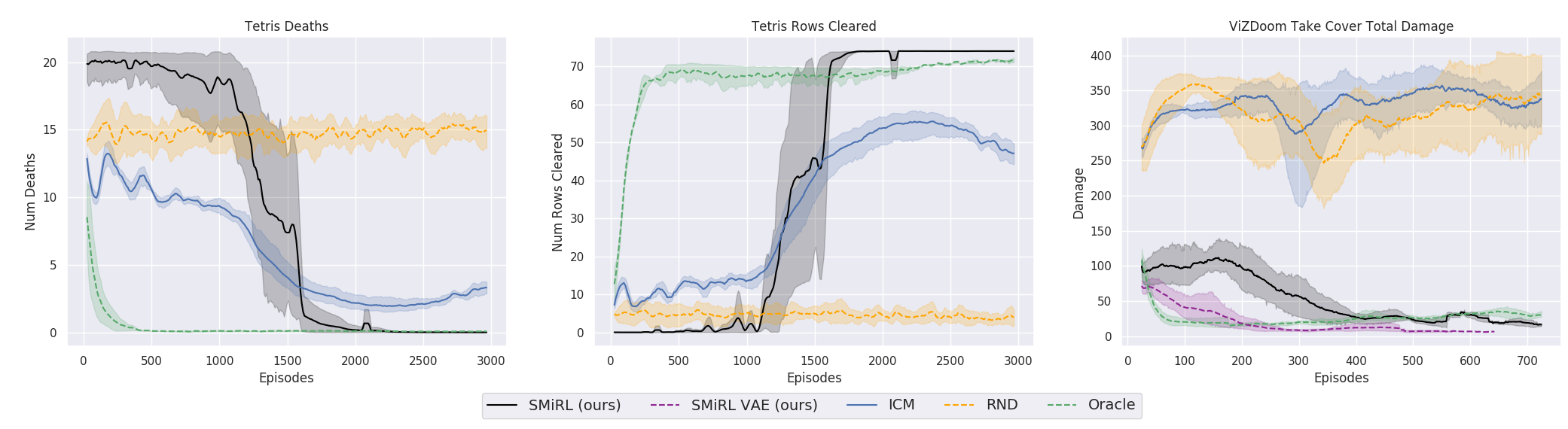
Но здесь нужно уточнить, что это только для окружений, которые исследователи использовали в своей работе. Они опасные, случайные, шумные и со все возрастающей энтропией. В них действительно может быть выгоднее ничего не делать. И лишь иногда активно шевелиться, когда в вас летит огненный шар или мост позади вас начинает разрушаться. Однако исследователи из Berkeley настаивают, видимо по своему нелегкому жизненному опыту, что такие окружения гораздо ближе к сложной реальной жизни, чем использовавшиеся ранее в обучении с подкреплением. Ну не знаю, не знаю. В моей жизни летящие в меня огненные шары из монстров и безлюдные лабириты с единственным выходом встречаются примерно с одинаковой частотой. Но нельзя отрицать, что предложенный подход, при всей его простоте, показал потрясающие результаты. Возможно, в будущем должны разумно сочетаться оба подхода — гомеостаз с сохранением положительного постоянства в отдаленной перспективе и любопытство для текущих исследований окружающей среды.
Автор: DesertFlow
Источник: https://habr.com/
Понравилась статья? Тогда поддержите нас, поделитесь с друзьями и заглядывайте по рекламным ссылкам!