
 Последние успехи глубинного обучения и нейросетей распространились на широкий спектр приложений и продолжают распространяться дальше: от машинного зрения до распознавания речи и на многие другие задачи. Свёрточные нейросети лучше всех проявляют себя в задачах на зрение, а рекуррентные нейросети показали успех в задачах обработки естественного языка, в том числе в приложениях машинного перевода. Но в каждом случае для каждой конкретной задачи проектируется специфическая нейронная сеть. Такой подход ограничивает применение глубинного обучения, потому что проектирование нужно выполнять снова и снова для каждой новой задачи.
Последние успехи глубинного обучения и нейросетей распространились на широкий спектр приложений и продолжают распространяться дальше: от машинного зрения до распознавания речи и на многие другие задачи. Свёрточные нейросети лучше всех проявляют себя в задачах на зрение, а рекуррентные нейросети показали успех в задачах обработки естественного языка, в том числе в приложениях машинного перевода. Но в каждом случае для каждой конкретной задачи проектируется специфическая нейронная сеть. Такой подход ограничивает применение глубинного обучения, потому что проектирование нужно выполнять снова и снова для каждой новой задачи.

Это также отличается от того, как работает человеческий мозг, который умеет обучаться нескольким задачам одновременно, да ещё извлекает выгоду из переноса опыта между задачами. Авторы научной работы «Одна модель для обучения всему» из группы Google Brain Team задались естественным вопросом: «Можем ли мы создать унифицированную модель глубинного обучения, которая будет решать задачи из разных областей?»

Оказалось, что можем. Google сделала это — и открыла Tensor2Tensor для всеобщего пользования, код опубликован на GitHub.
Вопрос создания многозадачных моделей был предметом многих научных работ и поднимался в литературе по глубинному обучению. Модели обработки естественного языка давным-давно показали повышение качества с использованием многозадачного подхода, а недавно модели машинного перевода и вовсе показали обучаемость без подготовки (zero-shot learning, когда задача решается без предоставления материалов для обучения решению этой задачи) при обучении одновременно на множестве языков. Распознавание речи тоже увеличило качество при обучении в таком многозадачном режиме, как и некоторые задачи в области машинного зрения, вроде распознавания вида лица. Но во всех случаях все эти модели обучались на задачах из того же домена: задачи по переводу — на других задачах по переводу (пусть и с других языков), задачи по машинному зрению — на других задачах по машинному зрению, задачи по обработке речи — на других задачах по обработке речи. Но не было предложено ни одной по-настоящему многозадачной мультимодельной модели.
Специалистам из Google удалось разработать такую. В научной статье они описывают архитектуру MultiModel — единой универсальной модели глубинного обучения, которая может одновременно обучаться задачам из разных доменов.

Архитектура MultiModel
В частности, исследователи для проверки обучали MultiModel одновременно на восьми наборах данных:
- Корпус распознавания речи WSJ
- База изображений ImageNet
- База обычных объектов в контексте COCO
- База парсинга WSJ
- Корпус перевода с английского на немецкий язык
- Обратное предыдущему: корпус перевода с немецкого на английский язык
- Корпус перевода с английского на французский язык
- Обратное предыдущему: корпус перевода с французского на английский язык
Модель успешно обучилась всем перечисленным задачам и показала неплохое качество работы: не выдающееся на данный момент, но выше, чем у многих специфических нейросетей, спроектированных под одну задачу.

На иллюстрации показаны некоторые примеры работы модели. Очевидно, что она умеет описывать текстом, что изображено на фотографии, проводить категоризацию объектов и осуществлять перевод.
Учёные подчёркивают, что это только первый шаг в данном направлении, но при этом обращают внимание на две ключевых инновации, которые сделали возможным создание такой модели в принципе и что они считают своим главным достижением:
- Маленькие подсети с ограниченной модальностью, которые превращаются в унифицированное представление и обратно. Для того, чтобы мультимодальная универсальная модель могла обучаться на входных данных разных форматов — тексте, звук, изображения, видео и т. д. — все они должны быть переведены в общее универсальное пространство представлений переменного размера.
- Вычислительные блоки различных видов критически важны для получения хороших результатов на различных проблемах. Например, блок Sparsely-Gated Mixture-of-Experts вставили для задач обработки естественного языка, но он не мешал производительности и на других задачах. Точно так же обстоит и с другими вычислительными блоками.
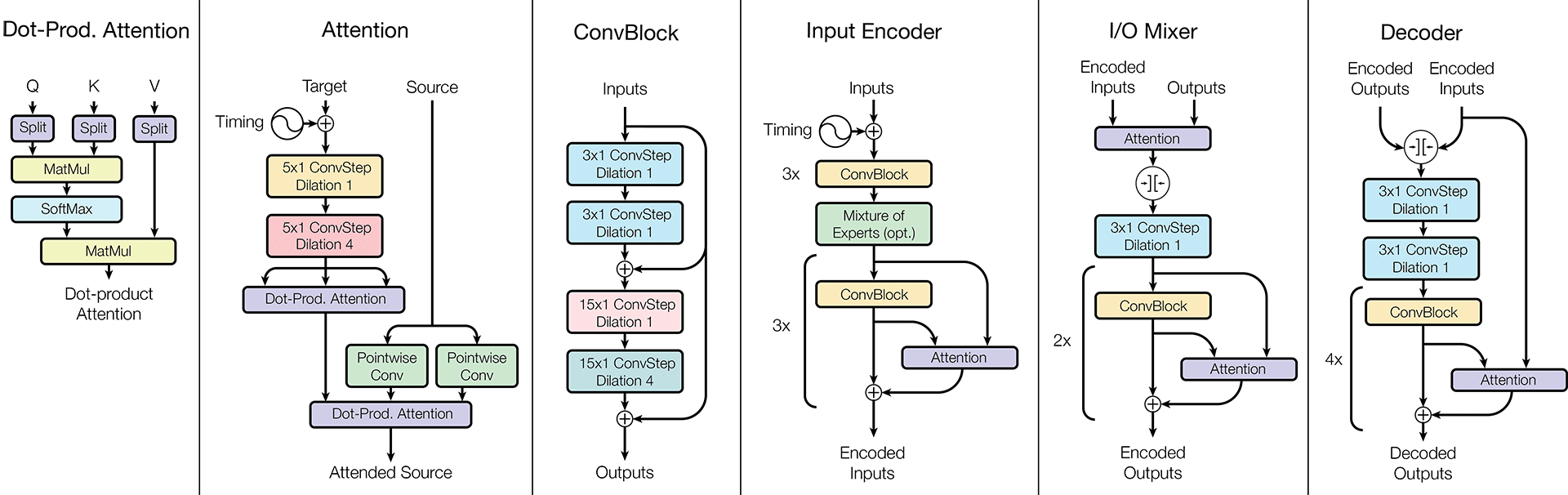
Более детальная архитектура MultiModel показана на иллюстрации выше.
MultiModel обучается сразу на многих данных и многих задачах. Эксперименты показали, что такой подход даёт огромное преимущество по улучшению качества работы на задачах с небольшим количеством данных. В то же время на задачах с большим количеством данных ухудшение наблюдается лишь незначительное, если вообще наблюдается.
Научная работа опубликована на сайте препринтов arXiv.org (arXiv:1706.05137).
Автор: Анатолий Ализар @alizar

Понравилась статья? Тогда поддержите нас, поделитесь с друзьями и заглядывайте по рекламным ссылкам!